python中使用selenium获取网页url并点击后,不知道怎么直接获取返回的requests url 的值,想要利用这个获取对应的小说
网页点击响应
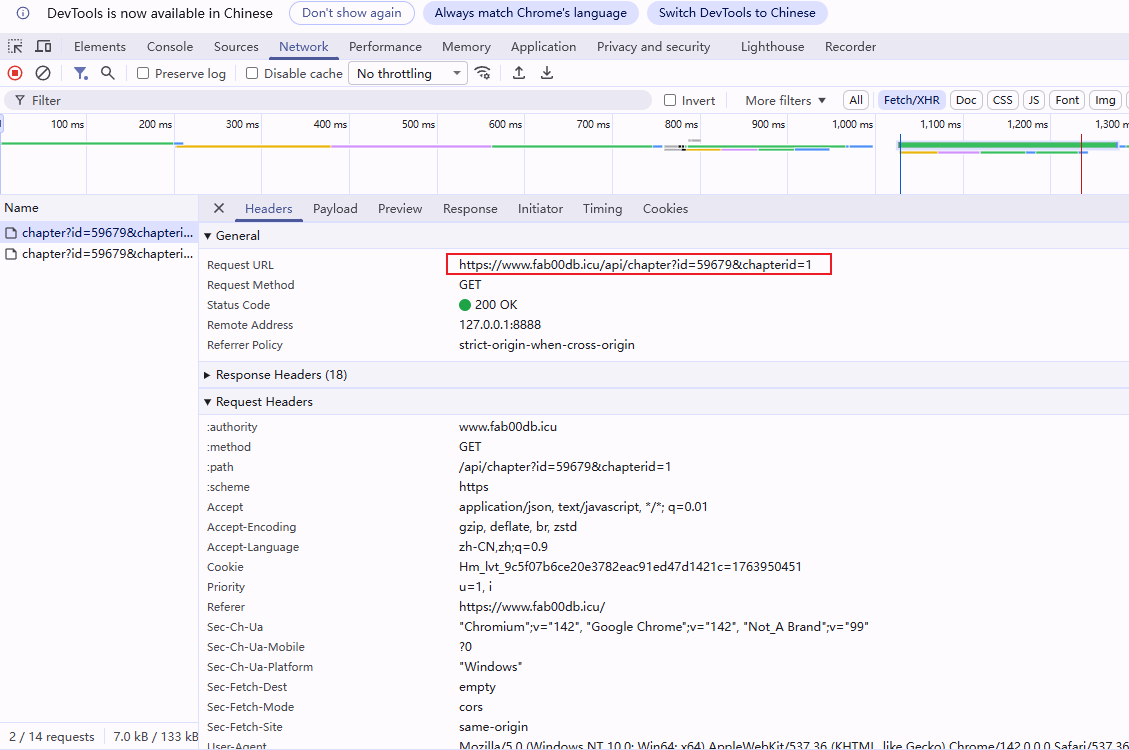
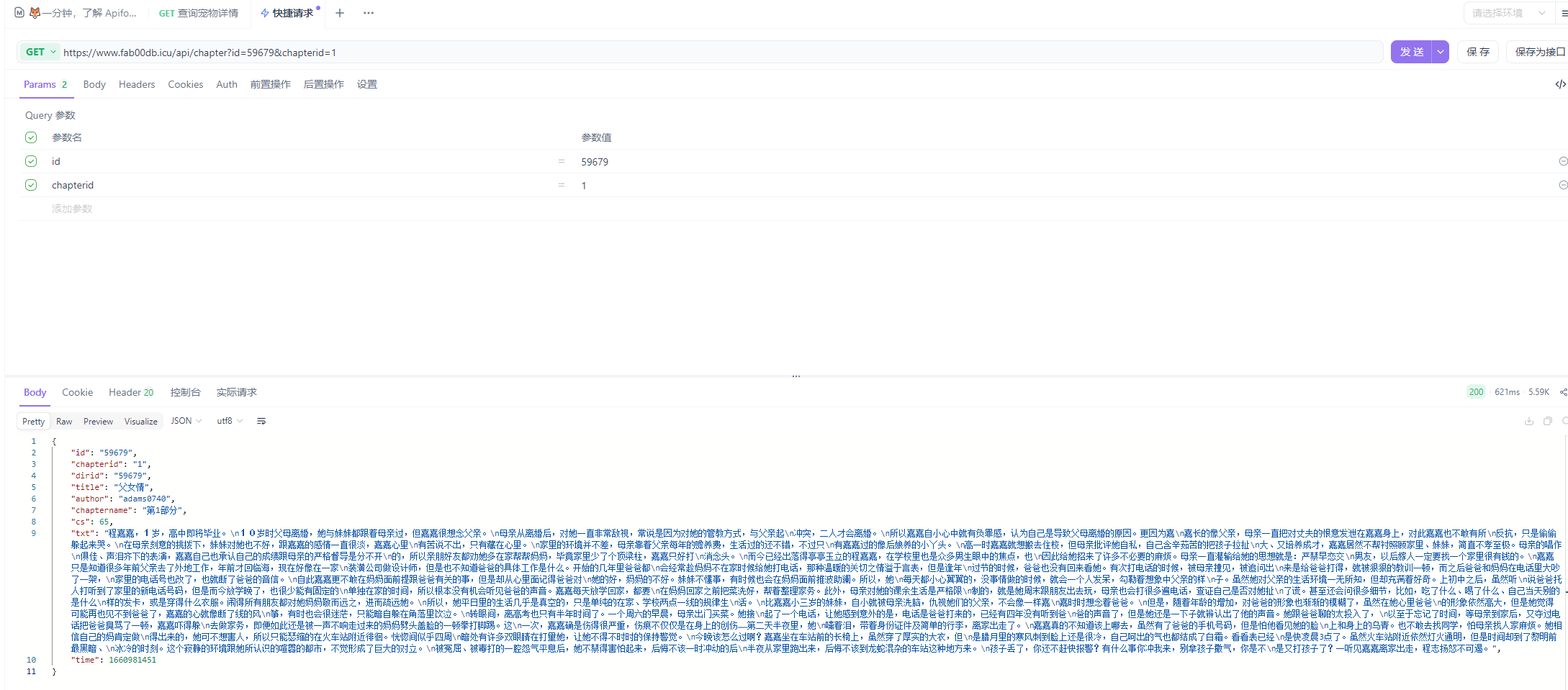
返回的request url 里边实际的值

python中使用selenium获取网页url并点击后,不知道怎么直接获取返回的requests url 的值,想要利用这个获取对应的小说
网页点击响应
返回的request url 里边实际的值
 分享
分享 实操可行方法,利用selenium的webdriver、Options方法启动带有性能监控功能的Chrome浏览器API
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
def __init__(self):
# 初始化浏览器实例
options = Options()
options.set_capability('goog:loggingPrefs', {'performance': 'ALL'})
self.driver = webdriver.Chrome(options=options)
获取浏览器的性能日志,遍历日志并解析json格式消息,判断符合条件url并返回
def get_request_url(self):
"""
初始化空字符串request_url
获取浏览器的性能日志
遍历每条日志,解析JSON格式的消息
查找网络请求开始发送的事件
检查请求URL是否包含章节标识符
找到匹配的URL后立即返回,否则返回None
:return:含 chapterid=1 的Request URL或None
"""
request_url = str()
logs = self.driver.get_log('performance')
for log in logs:
try:
message = json.loads(log['message'])
method = message.get('message', {}).get('method', '')
if method == 'Network.requestWillBeSent':
request_str = message['message']['params']['request']['url']
if self.settings.chapter_url_str in request_str:
request_url += request_str
except (json.JSONDecodeError, KeyError):
continue # 忽略解析失败的日志
return request_url
 系统已结题
12月7日
系统已结题
12月7日 已采纳回答
11月29日
创建了问题
11月25日
已采纳回答
11月29日
创建了问题
11月25日

