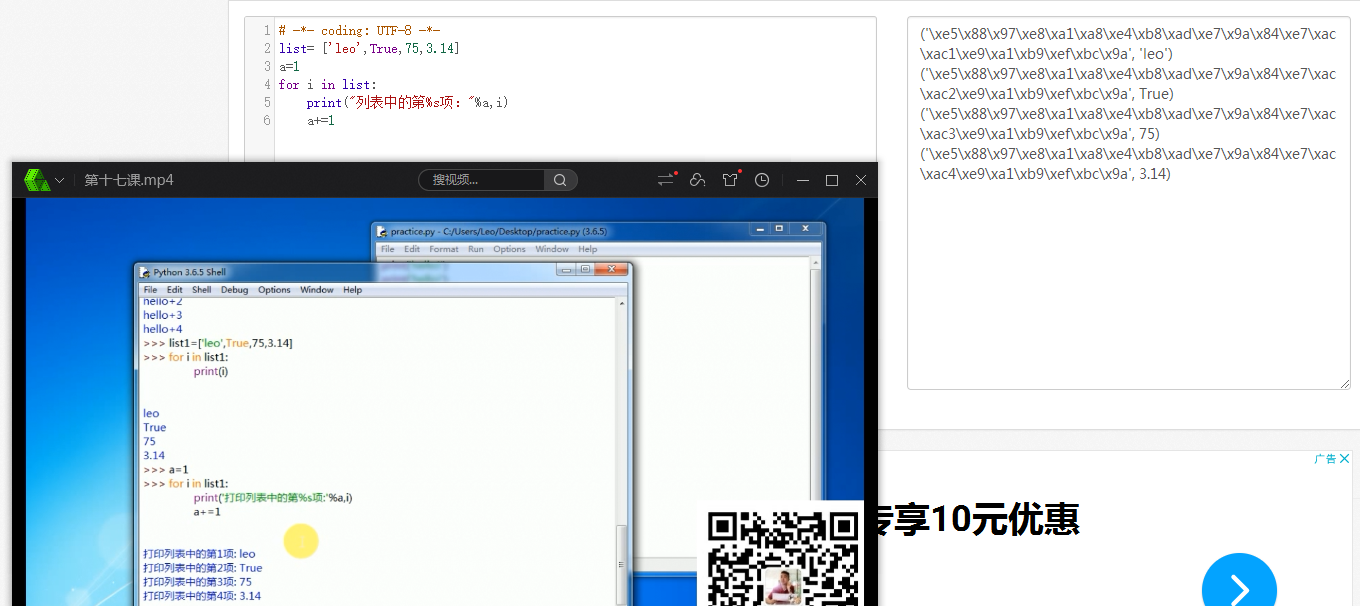
%a是什么意思?看一些资料说是占位符,然后我在一个学习视频里看到的和我自己在网上编译出来的是完全不同的效果,好像不知道应该怎么理解了,那么,%a到底是什么意思呢?
在C/C++里面%a,%A代表 读入一个浮点值(仅C99有效),那么在pyhton中又是什么意思呢?

%a是什么意思?看一些资料说是占位符,然后我在一个学习视频里看到的和我自己在网上编译出来的是完全不同的效果,好像不知道应该怎么理解了,那么,%a到底是什么意思呢?
在C/C++里面%a,%A代表 读入一个浮点值(仅C99有效),那么在pyhton中又是什么意思呢?
 分享
分享
你是说print里的%a? 这个本身当然没意义,“%s”%变量,这个是一种占位符的用法。
你这里的%s就是表示占了一个位置,这个位置是什么变量呢?就由%a来表达,然后a的值就会传递到这个位置进行输出。
谷歌搜索一下占位符的用法吧。
分享

