
问题内容:langchain的数据库检索和gradio搭配时性能下降
环境:
windows11
langchain 1.1.0
gradio 6.0.0
大模型API提供商:deepseek
嵌入模型:Qwen3-Embedding-0.6B
问题描述
起初使用langchain简单尝试了一下RAG,然后使用gradio作为前端展示,但是检测的时候发现在gradio中,langchain数据库的 vector_store.similarity_search() 检索会变得特别慢,达到二三十秒,但是如果不用gradio的话,检索只耗时零点几秒,尝试了不同的数据库 chromadb, FAISS, Qdrant结果都类似
- 下面以FAISS为例,做一个简单的问题复现
简单的完整代码复现
1. 不使用gradio
from langchain.chat_models import init_chat_model
from langchain.agents import create_agent
from langchain_community.vectorstores import FAISS
from langchain.tools import tool
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_core.messages import HumanMessage
import os
import time
import logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s', datefmt='%Y-%m-%d %H:%M:%S')
logger = logging.getLogger(__name__)
agent = None
vector_store = None
def create_vector(text_dir: str):
"""创建向量数据库"""
s_time = time.time()
global vector_store
loader = TextLoader(text_dir, encoding='utf-8')
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=20)
texts = text_splitter.split_documents(documents)
embedding = HuggingFaceEmbeddings(model_name="Qwen/Qwen3-Embedding-0.6B")
if vector_store is None:
vector_store = FAISS.from_documents(texts, embedding)
e_time = time.time()
logger.info(f"创建向量数据库耗时: {e_time - s_time:.2f} 秒")
@tool
def search_vector(query: str) -> str:
"""向量数据库检索故事信息"""
s_time = time.time()
global vector_store
if vector_store is None:
return "向量数据库未创建"
docs = vector_store.similarity_search(query, k=3)
result = "\n".join([doc.page_content for doc in docs])
e_time = time.time()
logger.info(f"向量数据库检索耗时: {e_time - s_time:.2f} 秒")
return result
def get_model():
"""返回聊天模型"""
return init_chat_model(
'deepseek-chat',
api_key = os.getenv('DEEPSEEK_API_KEY')
)
def get_agent():
"""生成Langchain Agent"""
s_time = time.time()
model = get_model()
agent = create_agent(
model=model,
tools=[search_vector],
system_prompt="你是一个有帮助的助手,擅长回答与提供的故事内容相关的问题。"
)
e_time = time.time()
logger.info(f"创建Agent耗时: {e_time - s_time:.2f} 秒")
return agent
if __name__ == "__main__":
# 以一段AI生成的短故事为例进行嵌入
create_vector('story_test.txt')
agent = get_agent()
# 这里为了测试方便,直接用invoke调用了
result = agent.invoke(
{'messages': [HumanMessage(content="请检索并简要描述故事的主角。")]}
)
print(f'AI: {result["messages"][-1].content}')
调用的截图如下:
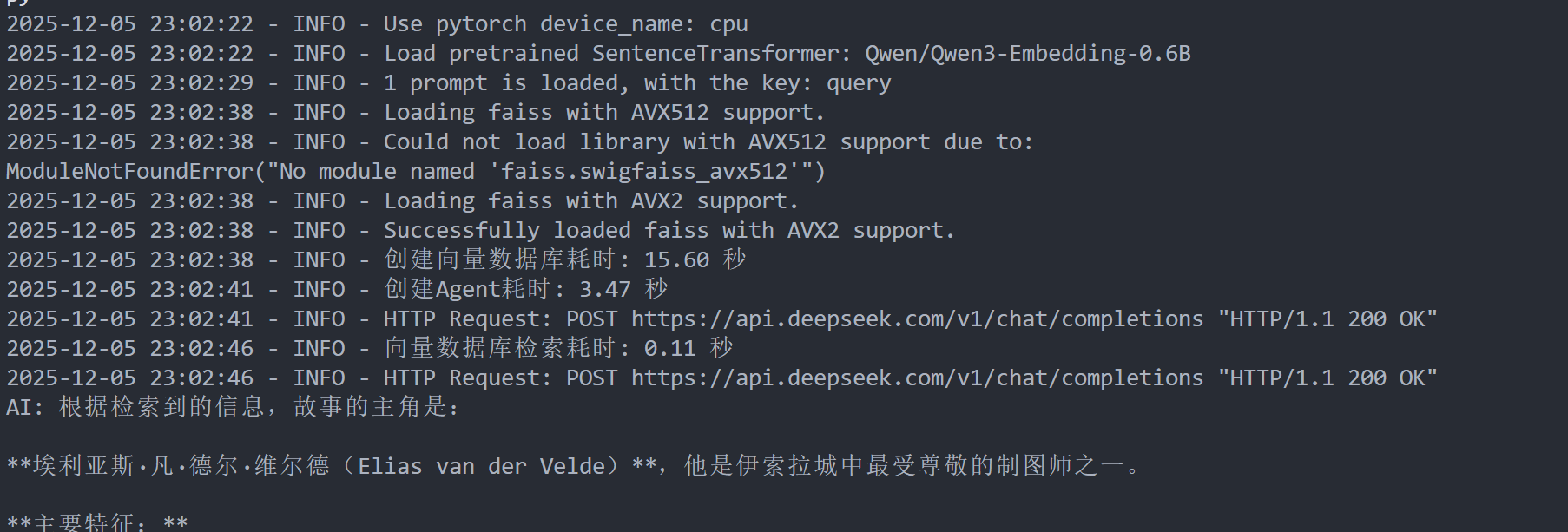
可以看到数据库检索是很快的,这次的示例中是0.1s
但是问题就出在部署到gradio
2. 使用gradio前端
#...前面代码不变
# main前加上gradio获取结果的函数
import gradio as gr
def get_result(msg, history):
"""获取AI回复结果"""
s_time = time.time()
if agent is not None:
result = agent.invoke(
{'messages': [HumanMessage(content=msg)]}
)
e_time = time.time()
logger.info(f"gradio 获取AI回复耗时: {e_time - s_time:.2f} 秒")
yield result["messages"][-1].content
if __name__ == "__main__":
create_vector('story_test.txt')
agent = get_agent()
# 启用gradio
gr.ChatInterface(
fn=get_result,
).launch()
结果截图如下:
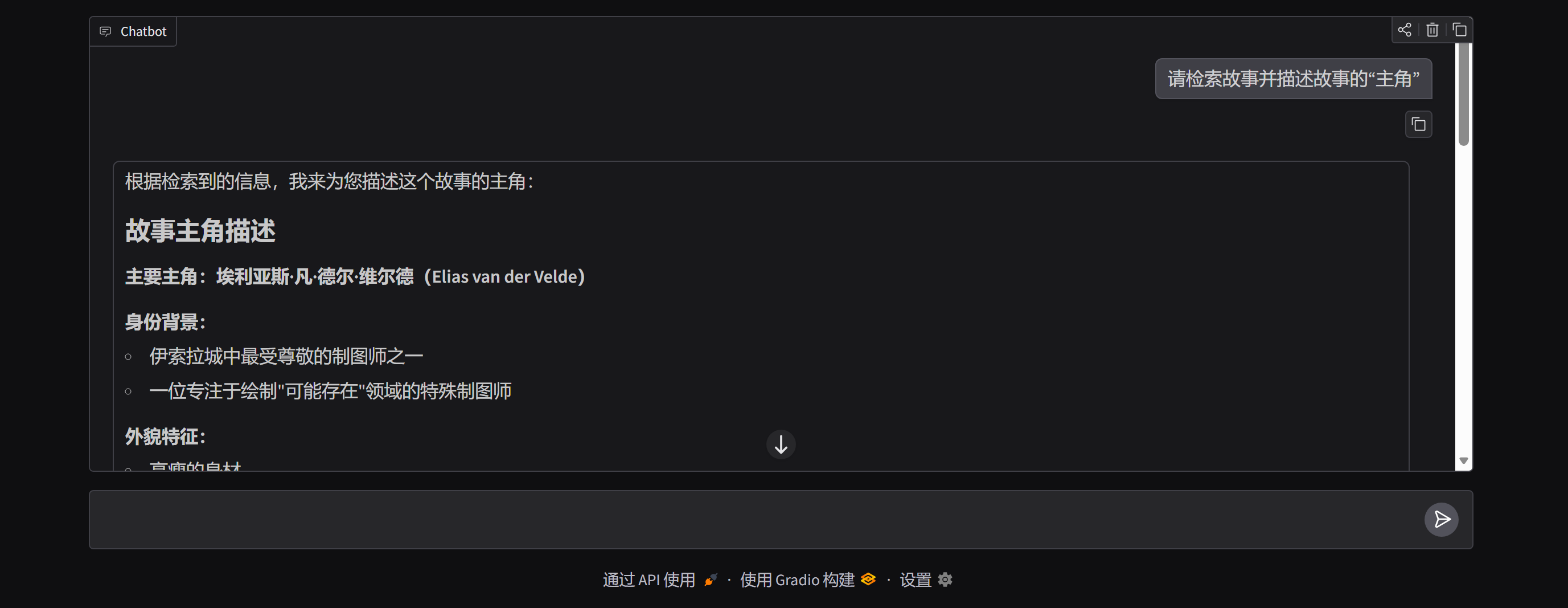
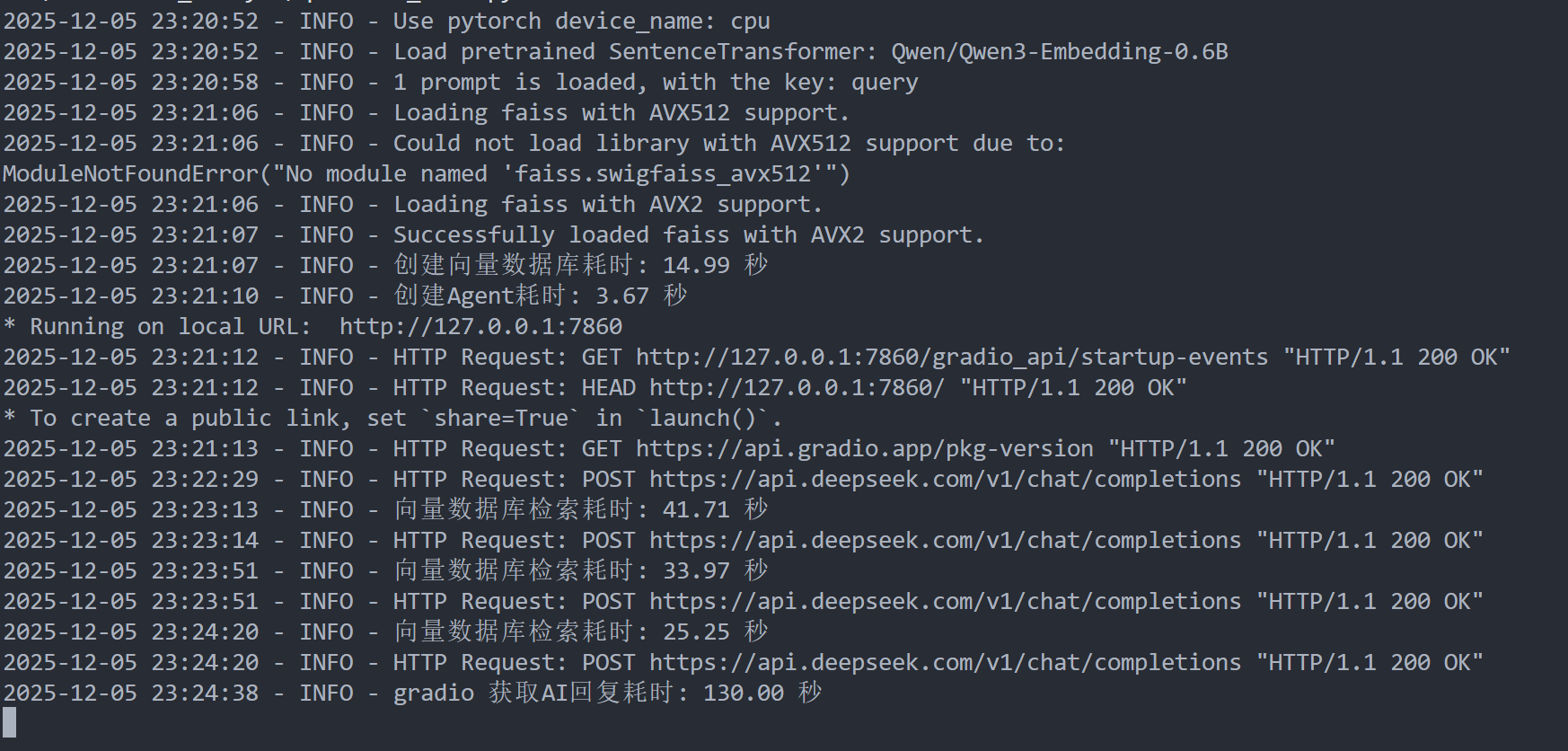
这次的测试中,agent多次检索了数据库以获取足够信息,但是每次的检索时长都大幅提升,从0.1s提升到了几十秒,而且从info信息来看,也没有出现重复初始化数据库或agent的情况,纯属是数据库检索变慢了
为了验证上述猜想,将**数据库检索步骤换成time.sleep()**,新的工具函数如下
@tool
def search_vector(query: str) -> str:
"""向量数据库检索故事信息"""
s_time = time.time()
global vector_store
if vector_store is None:
return "向量数据库未创建"
# docs = vector_store.similarity_search(query, k=3)
# result = "\n".join([doc.page_content for doc in docs])
time.sleep(3) # 模拟检索延时
result = '未检索到结果'
e_time = time.time()
logger.info(f"向量数据库检索耗时: {e_time - s_time:.2f} 秒")
return result
再次运行(把"故事"打成“古树”了,但这不重要)
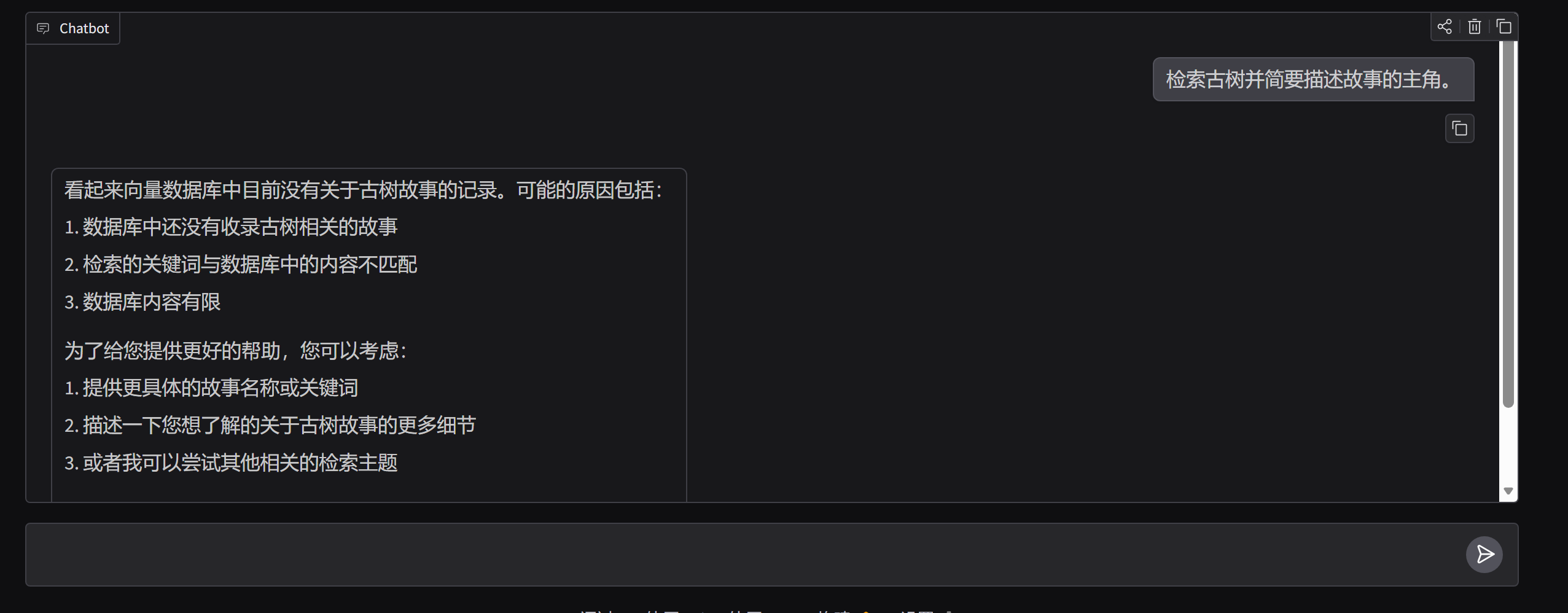
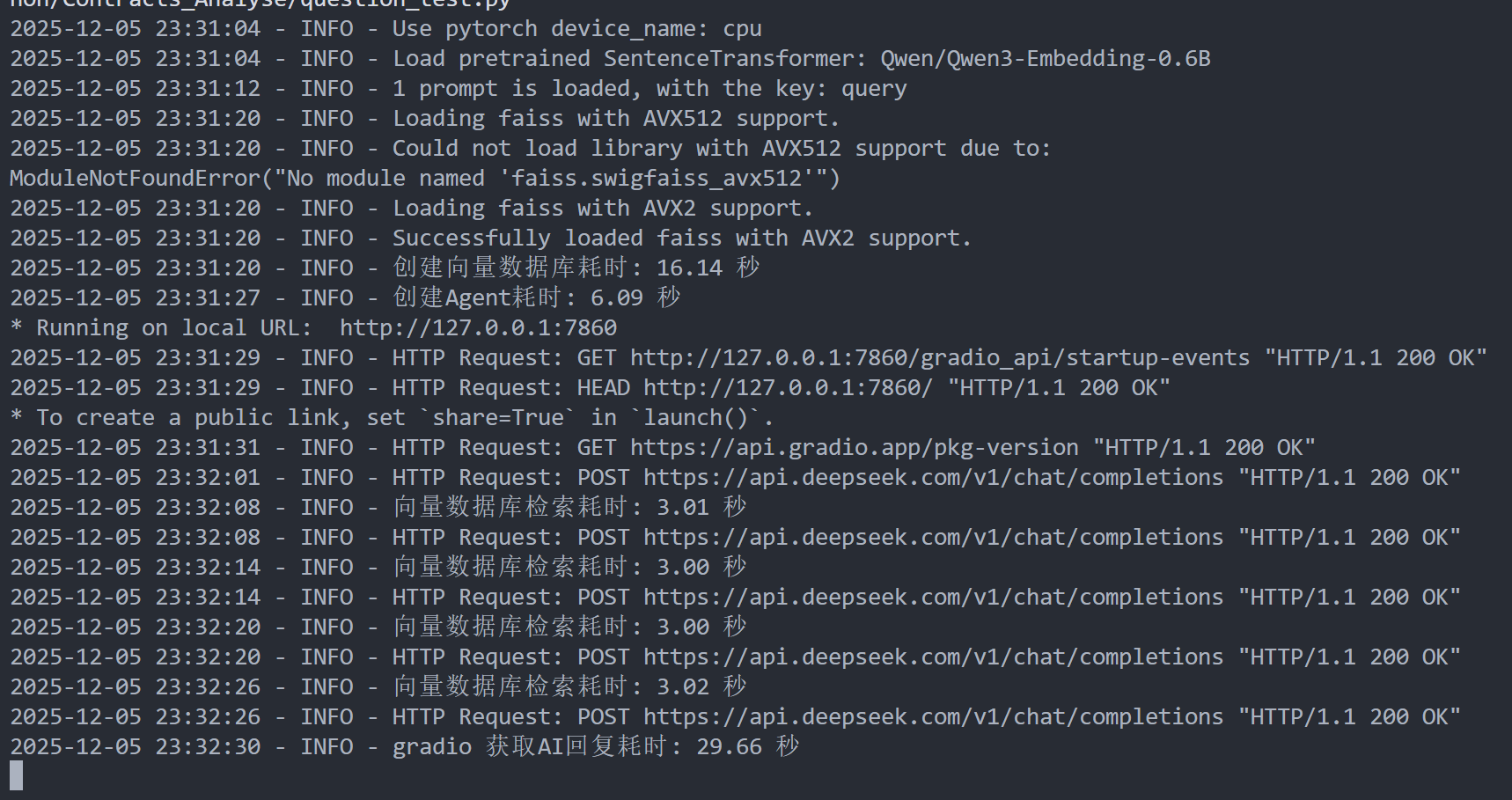
agent同样检索了很多次,这次每次的时间几乎就是 time.sleep()的时间,所以基本有充足理由确定在gradio中,AI回复变慢的原因是数据库检索 vector_store.similarity_search()性能大幅下降了。
这个问题困扰我很久了😭,大家在使用langchian时有类型的问题吗,可以分享一下解决经验吗?






