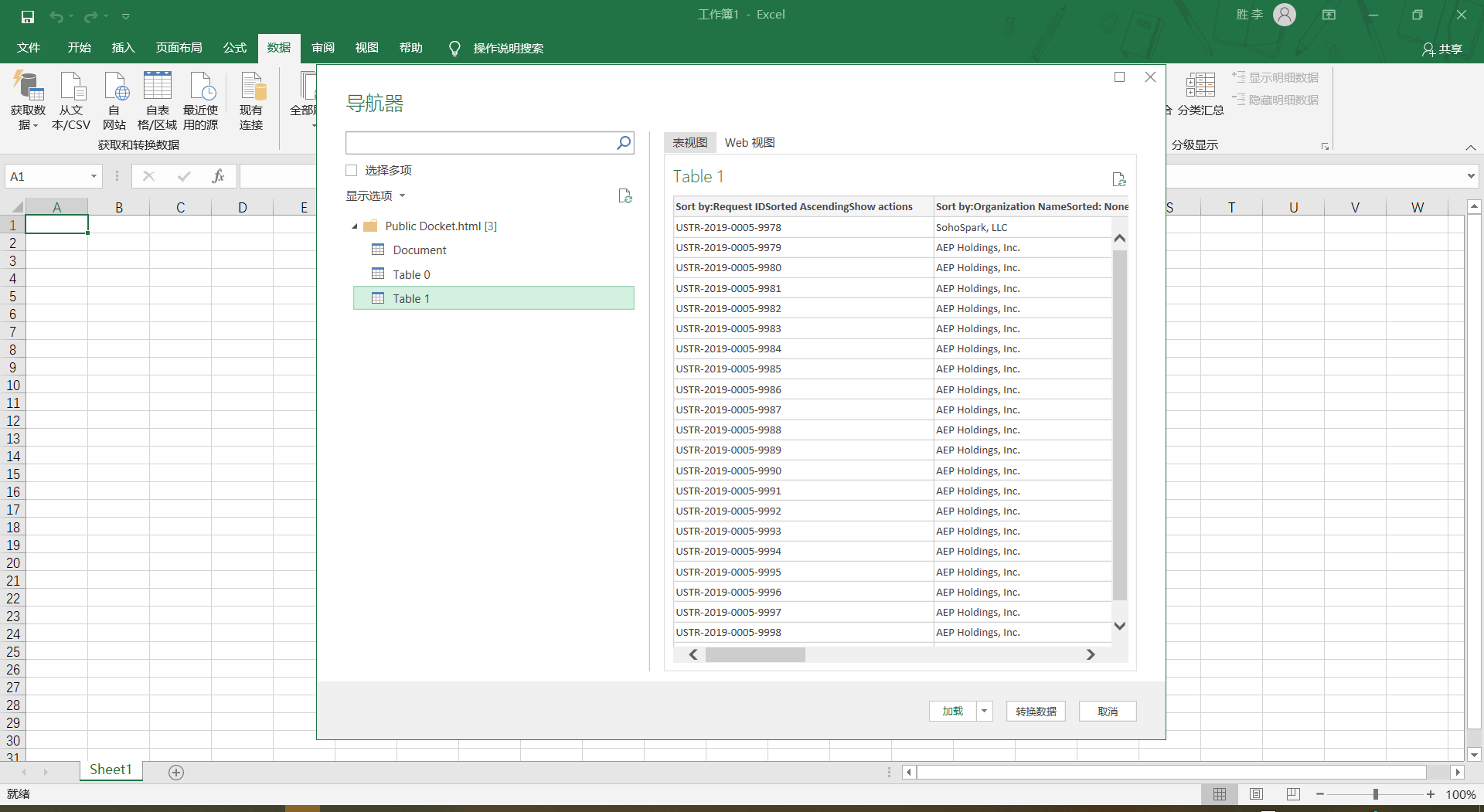
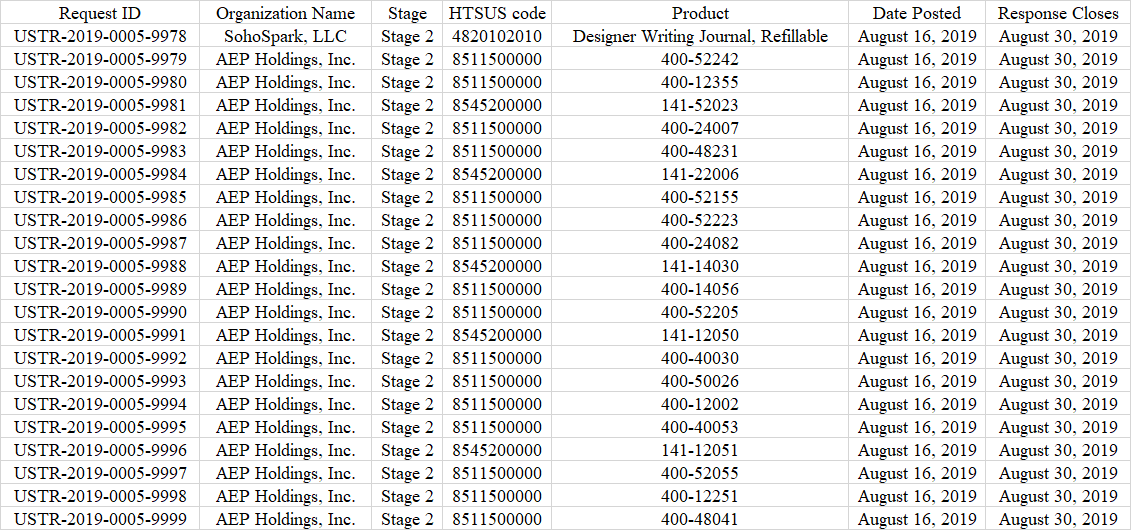
https://exclusions.ustr.gov/s/docket?docketNumber=USTR-2019-0005这是要爬的网站,我要抓那个表格的数据。
根据F12 我看到的Form data是
他的rep是这样的
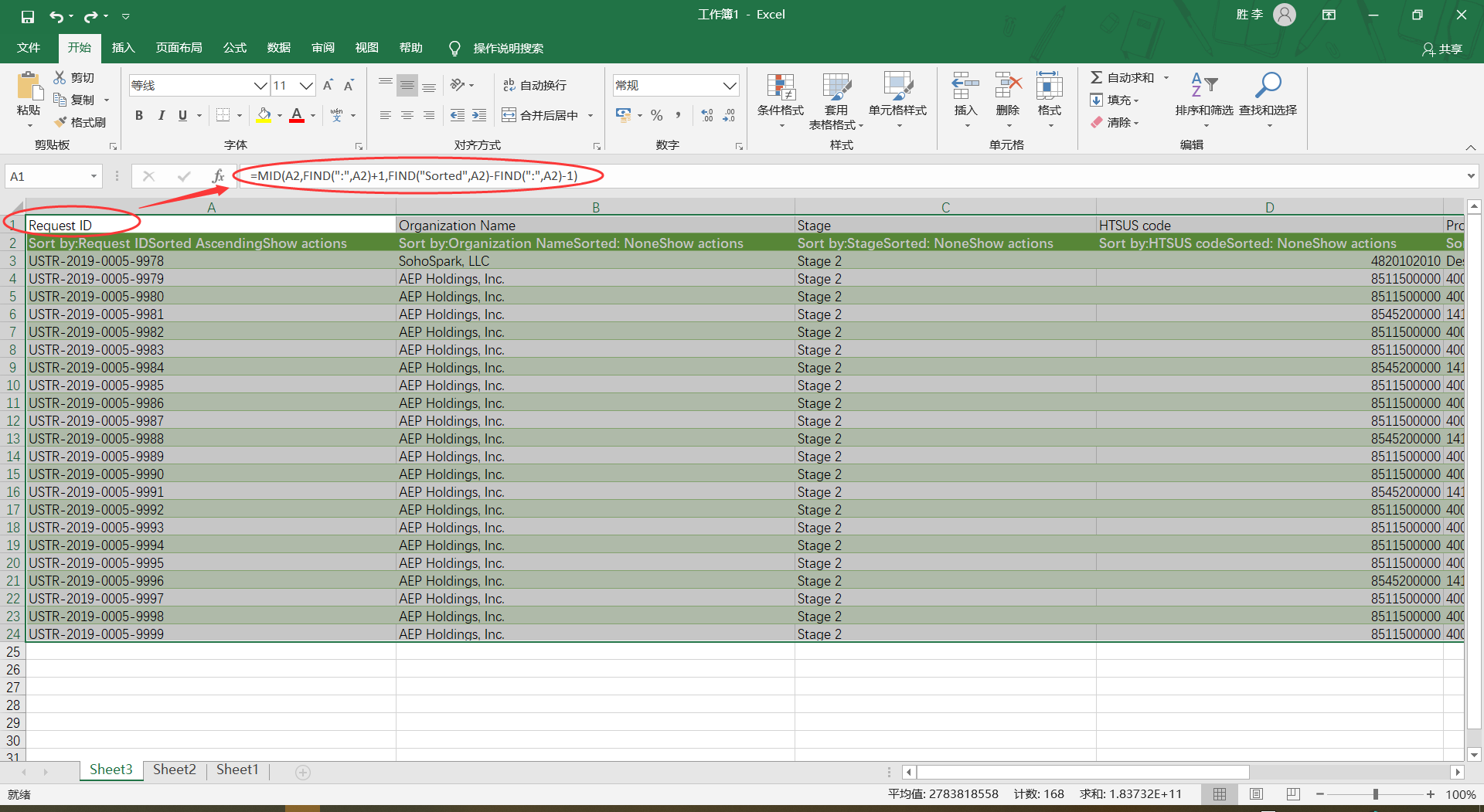
然后这是我的部分代码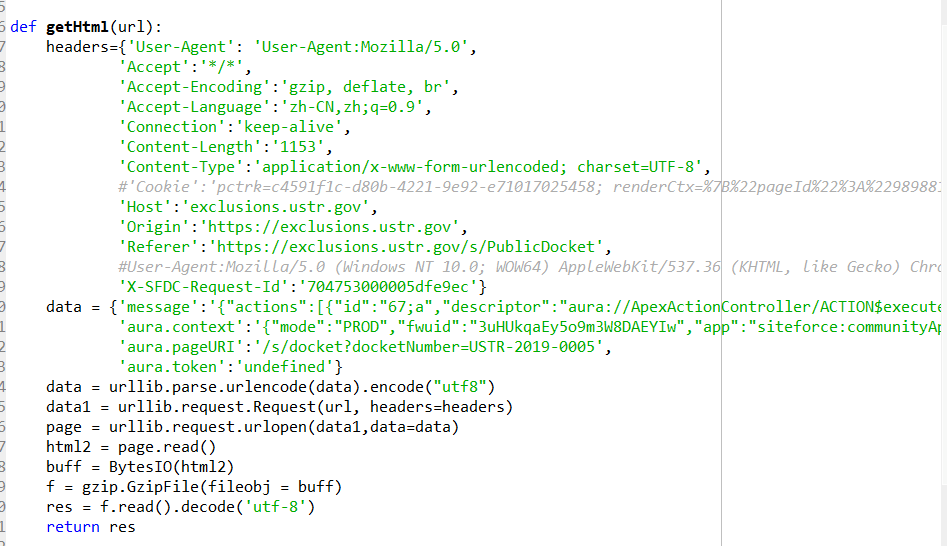
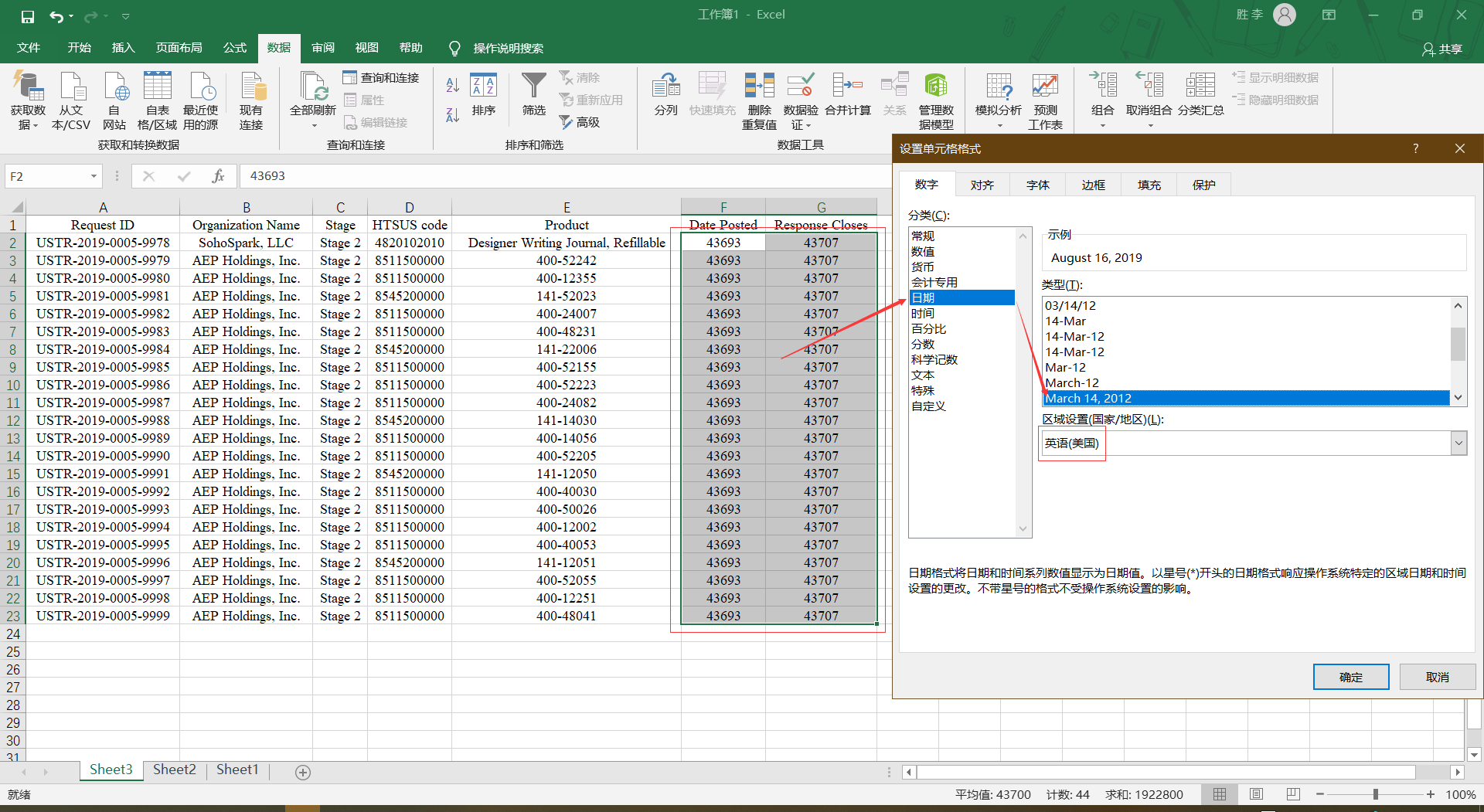
这是我代码运行的结果 、
、
这是我完整的代码
import json
import urllib
import gzip
from io import BytesIO
import ssl
ssl._create_default_https_context = ssl._create_unverified_context# 验证证书??不是很懂但是解决了SSL问题
def getHtml(url):
headers={'User-Agent': 'User-Agent:Mozilla/5.0',
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '1483',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
#'Cookie': 'pctrk=13806d4e-9502-4a46-b0a9-2dd0335ae056; renderCtx=%7B%22pageId%22%3A%2261489a7e-6511-4230-b9ed-bab5c8ff93b7%22%2C%22schema%22%3A%22Published%22%2C%22viewType%22%3A%22Published%22%2C%22brandingSetId%22%3A%2211600771-9799-46b6-9913-22cd8f714e32%22%2C%22audienceIds%22%3A%226Aut0000000PB9n%22%7D; oinfo=c3RhdHVzPUFDVElWRSZ0eXBlPTYmb2lkPTAwRHQwMDAwMDAwNFhMQw==; autocomplete=1; sid_Client=0000003KCN200000004XLC; clientSrc=222.68.18.123; inst=APPt; oid=00Dt00000004XLC; sid=00Dt00000004XLC!AQMAQHl3llX9OgfLSZgIaLL.z6gaelF3sYrH.QuZwNF1MIR6MR.k19Tfgn1O9Yd0hdFjMn1XQrgtdNQ6tv4MKhSLxjhTF4ET; __cfduid=d85b901ba5cd527ea8548a447e8f01b5a1572504746',
'Host': 'exclusions.ustr.gov',
'Origin': 'https://exclusions.ustr.gov',
'Referer': 'https://exclusions.ustr.gov/s/docket?docketNumber=USTR-2019-0005',
#User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36
'X-SFDC-Request-Id': '11312554500007b083'}
data = {'message': '{"actions":[{"id":"68;a","descriptor":"aura://ApexActionController/ACTION$execute","callingDescriptor":"UNKNOWN","params":{"namespace":"","classname":"ustrPublicDocketAuraService","method":"getPageRecords","params":{"selectorJSON":"{\"docketNumber\":\"USTR-2019-0005\",\"filteredBy\":\"\",\"sortedBy\":\"Name\",\"sortedDirection\":\"asc\",\"lastSortedByValue\":null,\"lastRequestNumber\":null,\"startIndex\":50,\"endIndex\":100}"},"cacheable":false,"isContinuation":false}}]}',
'aura.context': '{"mode":"PROD","fwuid":"3uHUkqaEy5o9m3W8DAEYIw","app":"siteforce:communityApp","loaded":{"APPLICATION@markup://siteforce:communityApp":"vc87DBrWuhFjIBDb5BvCxQ"},"dn":[],"globals":{},"uad":false}',
'aura.pageURI': '/s/docket?docketNumber=USTR-2019-0005',
'aura.token': 'undefined'}
data = urllib.parse.urlencode(data).encode("utf-8")
data1 = urllib.request.Request(url, headers=headers)
page = urllib.request.urlopen(data1,data=data)
html2 = page.read()
buff = BytesIO(html2)
f = gzip.GzipFile(fileobj = buff)
res = f.read().decode('utf-8')
return res
url = 'https://exclusions.ustr.gov/s/sfsites/aura?r=8&aura.ApexAction.execute=1'
#url = 'https://www.baidu.com'
a = getHtml(url)
print(a)