上午好☀️☀️☀️️
本答案参考通义千问
你的疑问非常有代表性,也触及了MySQL 查询优化中一个重要的概念:“借索引”(Index Hints)与覆盖索引(Covering Index)。我们来详细分析一下你提到的 SQL 语句和导师建议的修改方式,并解释为什么“借索引”可以提速。
一、问题背景
你当前的 SQL 是这样的:
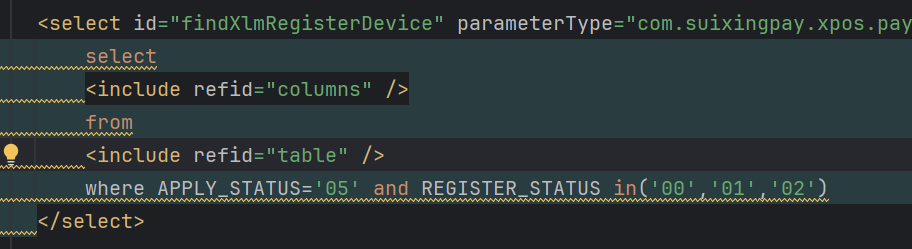
SELECT * FROM table_name
WHERE field1 = 'value' AND field2 = 'value';
field1 和 field2 都不是索引字段。- 表中只有
submit_time 和 id 字段有索引。 - 因此,这条 SQL 会进行全表扫描,随着数据量增加,性能会急剧下降。
二、导师建议的修改方式
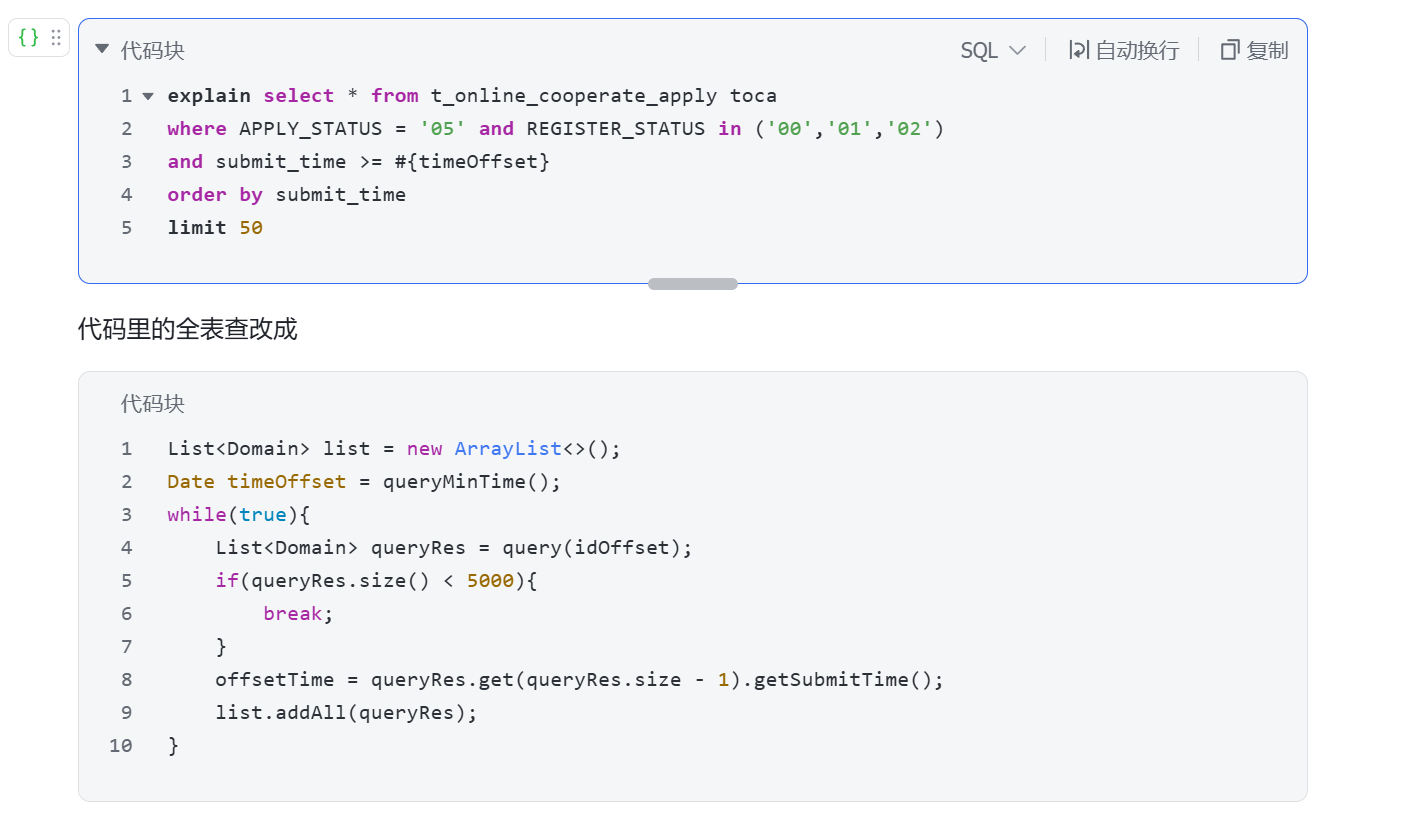
导师建议将 SQL 改为:
SELECT id, submit_time FROM table_name
WHERE field1 = 'value' AND field2 = 'value'
LIMIT 5000;
注意:这里只查询了 id 和 submit_time,而不是 *。
三、导师说的“借索引”是什么意思?
3.1 什么是“借索引”?
“借索引”是指在查询中使用了某个字段的索引,即使该字段并不是查询条件中的字段,但通过覆盖索引的方式,让 MySQL 可以直接从索引中获取所需的数据,而不需要回表查询主表。
3.2 为什么这个修改可以提速?
- 原 SQL 需要全表扫描,时间复杂度是 O(n),n 是行数。
- 修改后的 SQL 虽然仍然需要过滤
field1 和 field2 的值,但由于只查询了 id 和 submit_time,这两个字段恰好有索引。 - MySQL 可以利用 覆盖索引(Covering Index)来避免回表,从而加快查询速度。
四、关键点详解
4.1 覆盖索引(Covering Index)
如果查询的字段全部包含在某个索引中,那么这个查询就可以完全通过索引来完成,不需要访问实际的数据行。
例如:
- 索引是
(id, submit_time) - 查询是
SELECT id, submit_time FROM ... - 则可以直接从索引中获取数据,无需回表。
4.2 为什么不能直接用 WHERE field1 = 'value' AND field2 = 'value' 做索引?
因为 field1 和 field2 没有索引,所以 MySQL 无法使用索引来加速这个查询条件。
五、为什么导师说“借索引”能提速?
虽然 field1 和 field2 没有索引,但如果你的查询只返回 id 和 submit_time,并且这两个字段有索引,那么:
MySQL 可以通过索引快速定位到符合条件的记录,然后直接从索引中提取需要的数据(即“借索引”),无需回表。
这其实是一种间接的索引使用,虽然不是直接对 field1 和 field2 使用索引,但通过限制返回字段,结合已有索引,实现了更快的查询。
六、总结:为什么这样可以提速?
| 原因 | 说明 |
|------|------|
| 覆盖索引 | 查询字段都包含在索引中,无需回表 |
| 减少数据量 | LIMIT 5000 减少了实际需要处理的数据量 |
| 索引范围扫描 | 如果 submit_time 有索引,且 field1 和 field2 的组合有部分筛选作用,可能触发索引范围扫描 |
| 减少 I/O 操作 | 从索引读取数据比从表中读取数据更快 |
七、如何进一步优化?
7.1 建立复合索引
如果你经常使用 field1 = 'value' AND field2 = 'value' 来查询,建议建立一个复合索引:
CREATE INDEX idx_field1_field2 ON table_name (field1, field2);
这样,MySQL 就可以直接使用这个索引来加速查询,不再需要“借索引”。
7.2 使用索引提示(Index Hints)
如果你希望强制使用某个索引,可以使用 USE INDEX:
SELECT * FROM table_name
USE INDEX (idx_field1_field2)
WHERE field1 = 'value' AND field2 = 'value'
LIMIT 5000;
八、结论
✅ 导师的说法是正确的,这种修改确实可以提升查询性能,原因如下:
- 利用了覆盖索引,减少了回表操作;
- 限制了结果集大小,降低了 I/O 和内存消耗;
- 间接使用了已有的索引字段,提高了查询效率。
虽然它并不能像直接对 field1 和 field2 建索引那样高效,但在没有其他索引的情况下,这是一个有效的优化手段。
九、推荐的优化步骤
- 检查索引情况,确认哪些字段有索引;
- 分析查询语句,看是否可以通过覆盖索引优化;
- 考虑建立复合索引,针对常用查询条件;
- 使用
EXPLAIN 分析执行计划,查看是否真的使用了索引; - 添加 LIMIT 或分页,控制结果集大小,提高性能。
如果你愿意,也可以提供具体的 SQL 和表结构,我可以帮你进一步分析和优化。