python中读取csv文件中的格式问题
文件中的数据是open列是第一列:
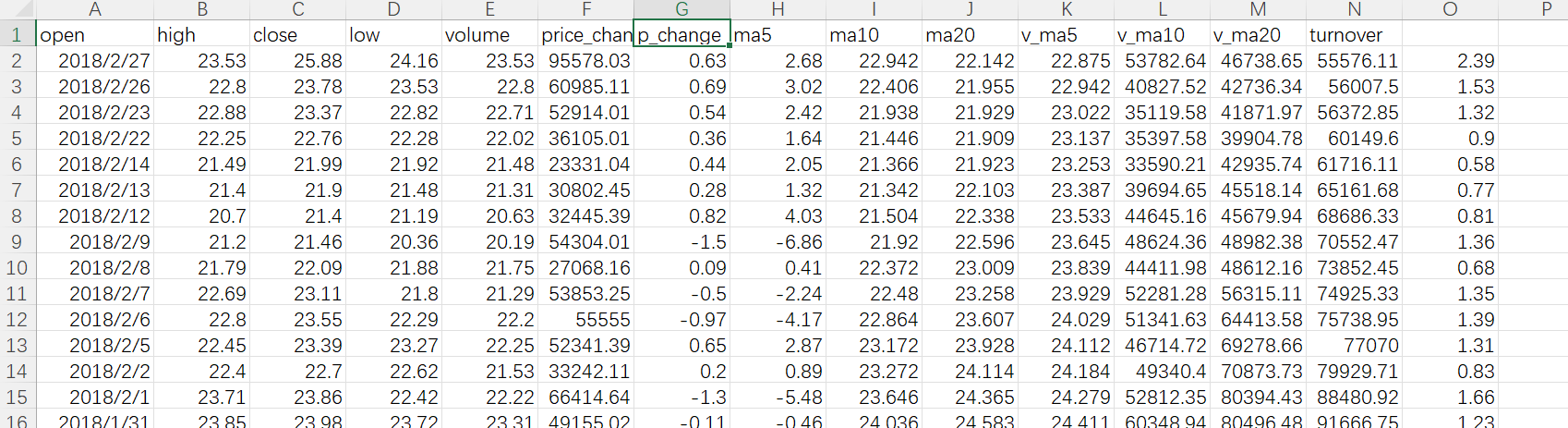
读取成DataFrame后open为什么对应的是第二列了?

 分享
分享
 关注
关注让 “紫雾凌寒” 来帮你回答,本回答结合 DeepSeek
如果还有问题,请评论或点击头像私信,如果有帮助到您, 请关注、采纳、点赞
df = pd.read_csv(‘your_file.csv’, names=[‘open’, ‘other_column1’, ‘other_column2’,…])
- 这里`names`参数指定了CSV文件各列对应的列名,按照实际CSV文件中的列顺序依次填写。如果不知道所有列名,可以先不指定`names`参数读取,然后再调整列顺序。例如:python
df = pd.read_csv(‘your_file.csv’)
df = df[[‘open’, ‘other_column1’, ‘other_column2’,…]]
``
- 这种方式先按默认方式读取,然后通过重新排列列的顺序来达到正确的列顺序。
3. **方案优缺点**:
- **指定列名方式**:
- **优点**:直接确保了列名的正确顺序,代码简单直观,一开始就按照预期的列名读取文件,后续处理更方便。
- **缺点**:需要准确知道CSV文件中所有列的顺序和列名,如果列名或顺序有误,会导致数据读取错误。
- **先默认读取再调整顺序方式**:
- **优点**:不需要一开始就准确知道所有列名,先读取文件再调整列顺序更灵活。
- **缺点**:多了一步调整列顺序的操作,如果文件列数较多,调整列顺序可能会比较麻烦,且可能引入更多潜在的错误。
4. **总结**:
- 读取CSV文件时列顺序出错通常是由于未正确指定列名。可以通过指定names`参数或者先默认读取再调整列顺序的方式来解决。指定列名方式简单直接,但需要准确的列名信息;先默认读取再调整顺序方式更灵活,但多了一步操作。根据具体情况选择合适的方法来确保列顺序正确。
希望以上解答对您有所帮助。如果您有任何疑问,欢迎在评论区提出。
分享 创建了问题
1月12日
创建了问题
1月12日


