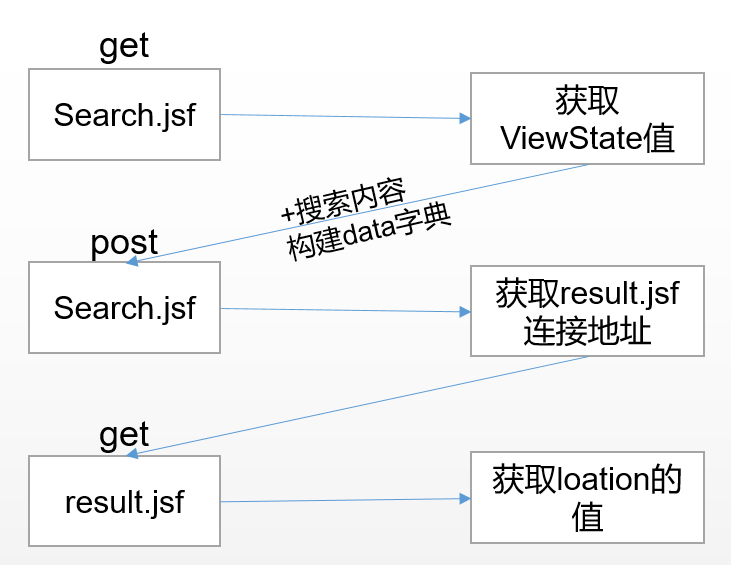
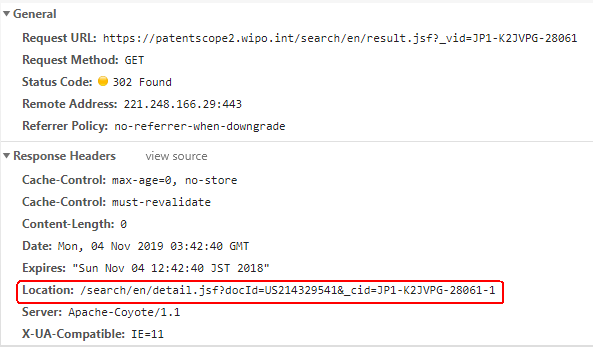
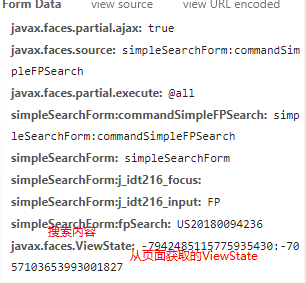
在Python中使用爬虫处理重定向页面时,您可以使用requests库来获取重定向后地址的响应头信息。requests库提供了一个allow_redirects参数,可以控制是否允许重定向。当设置allow_redirects=True时,requests库将自动处理重定向,并返回最终重定向后的响应。
以下是一个示例代码,演示如何获取重定向后地址的响应头内容:
import requests
url = 'http://example.com/redirect-page'
response = requests.get(url, allow_redirects=True)
final_url = response.url
response_headers = response.headers
print('Final URL:', final_url)
print('Response Headers:', response_headers)
在上述代码中,我们使用requests.get方法发送GET请求,并将allow_redirects参数设置为True,以允许重定向。然后,我们可以通过response.url获取最终重定向后的地址,通过response.headers获取响应头信息。
请注意,如果重定向过程涉及多个跳转,response.url将给出最终重定向的地址。而response.history属性将包含中间所有跳转的历史记录。
通过这种方式,您可以获取重定向后地址的响应头内容。您可以根据需要进一步处理响应头信息,例如提取特定的头字段值或进行其他操作。
注意:在实际使用中,请遵守网站的规则和法律法规,确保您的爬取行为符合合法和道德的要求。