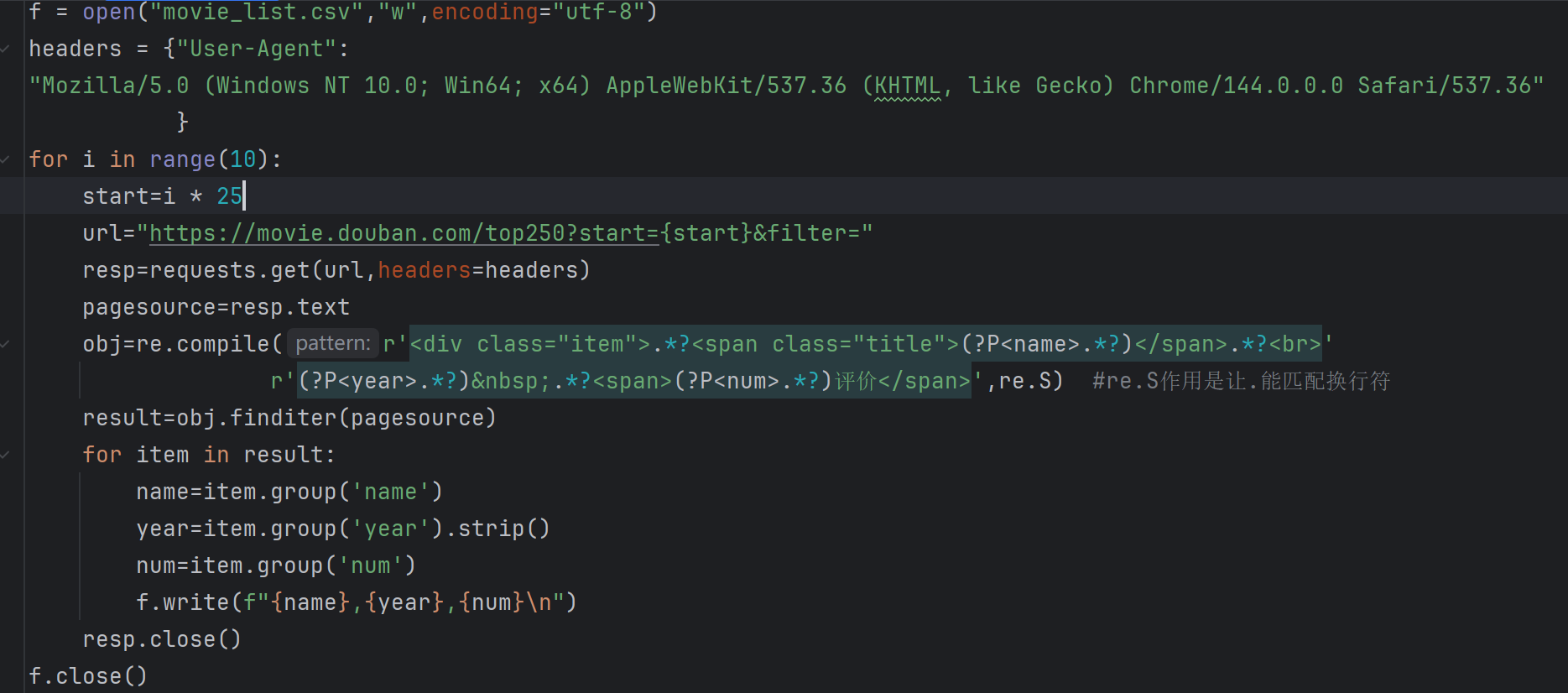
如图,我是哪里出问题了,自我感觉是循环这一块没写对,该怎么改,这个代码写的是一个翻页抓取的爬虫

如图,我是哪里出问题了,自我感觉是循环这一块没写对,该怎么改,这个代码写的是一个翻页抓取的爬虫
 分享
分享
下午好🌅🌅🌅
本答案参考通义千问
你提到爬虫抓取的数据是不断重复的,这通常意味着你的爬虫在翻页过程中没有正确处理下一页的请求,或者循环逻辑中存在错误,导致爬虫一直在抓取相同的内容。
翻页逻辑错误:
page=1, page=2)未递增或未更新。循环条件设置不当:
数据去重机制缺失:
网页结构变化:
确保 URL 是动态生成的,例如:
base_url = "https://example.com/page/"
for page in range(1, 10): # 假设最多翻10页
url = base_url + str(page)
# 发起请求
确认是否有“下一页”按钮或链接,如果有的话,可以提取该链接并继续请求。
requests.get(url),请确保每次请求的 url 不同。url,查看是否重复。from bs4 import BeautifulSoup
import requests
def get_next_page(soup):
next_link = soup.select_one('a.next') # 根据实际网页结构调整选择器
if next_link:
return next_link['href']
return None
current_url = "https://example.com/page/1"
while current_url:
response = requests.get(current_url)
soup = BeautifulSoup(response.text, 'html.parser')
# 处理当前页面数据
current_url = get_next_page(soup)
set())来存储已抓取的 ID 或标题,避免重复保存:
scraped_ids = set()
for item in items:
item_id = item.get('id') # 根据实际数据结构调整
if item_id not in scraped_ids:
scraped_ids.add(item_id)
# 保存数据
print() 或使用 logging 模块输出当前抓取的页面信息和数据内容,便于排查问题:
print(f"正在抓取页面: {current_url}")
print(f"抓取到的数据: {items}")
假设你原来的代码如下:
import requests
from bs4 import BeautifulSoup
url = "https://example.com/page/1"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
for item in soup.select('.item'):
print(item.text)
这段代码只抓取了第一页,不会自动翻页。如果你希望翻页,应该改写为:
import requests
from bs4 import BeautifulSoup
base_url = "https://example.com/page/"
scraped_ids = set()
for page in range(1, 11): # 假设最多翻10页
url = base_url + str(page)
print(f"正在抓取页面: {url}")
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
items = soup.select('.item')
for item in items:
item_id = item.get('id') # 根据实际情况获取唯一标识
if item_id and item_id not in scraped_ids:
scraped_ids.add(item_id)
print(item.text)
| 问题 | 解决方案 | |------|----------| | 翻页逻辑错误 | 确保 URL 动态生成,使用正确的翻页参数 | | 循环条件错误 | 添加判断是否还有下一页的逻辑 | | 数据重复 | 使用集合进行去重处理 | | 调试困难 | 添加打印或日志输出 |
如果你能提供具体的代码片段或截图,我可以进一步帮你定位问题所在。欢迎补充更多细节!
分享 创建了问题
1月24日
创建了问题
1月24日

