langchain4j 1.9.1版本调用本地使用vllm-openai部署的大模型报错
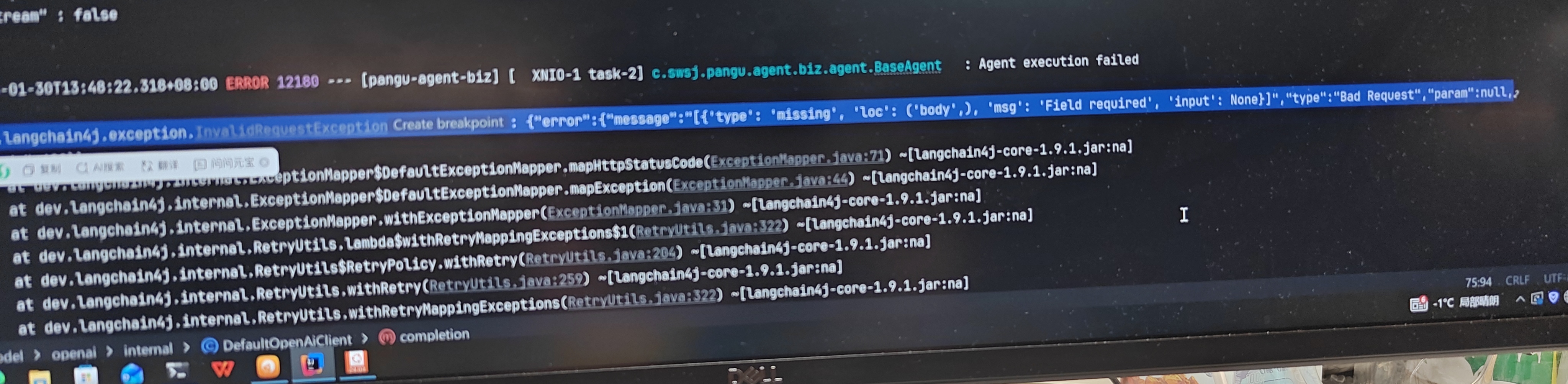

langchain4j 1.9.1版本调用本地使用vllm-openai部署的大模型报错
 分享
分享
上午好☀️☀️☀️️
本答案参考通义千问
在使用 LangChain4j 1.9.1 调用本地通过 vLLM-OpenAI 部署的大模型时,如果出现报错,可能是由于以下原因导致的。下面我将详细分析可能的原因,并提供解决方案。
你正在使用 LangChain4j 1.9.1 调用本地部署的 vLLM-OpenAI 大模型,但出现了错误。这通常涉及:
确保你的 vLLM-OpenAI 服务已经成功启动,并监听了正确的端口(默认为 http://localhost:8000)。
curl 测试 API 是否可用:
curl -X POST http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{"model": "your-model-name", "prompt": "Hello, world!"}'
LangChain4j 使用 OpenAI 接口与大模型交互,因此需要正确配置 API 地址和密钥(虽然 vLLM-OpenAI 不需要密钥,但需指定正确的 URL)。
在代码中配置正确的 API 地址,例如:
OpenAiClient openAiClient = OpenAiClient.builder()
.baseUrl("http://localhost:8000") // 注意:这里不是 OpenAI 官方地址
.build();
注意:vLLM-OpenAI 并不支持完整的 OpenAI API,某些功能可能不兼容,建议查看其文档确认支持的接口。
vLLM-OpenAI 启动时需要指定模型路径,如果模型路径不正确或模型未加载,会导致调用失败。
确保启动命令中指定了正确的模型路径,例如:
vllm serve --model /path/to/your/model --host 0.0.0.0 --port 8000
如果模型未加载完成,可能会导致调用时抛出异常。
LangChain4j 1.9.1 是一个较新的版本,而 vLLM-OpenAI 可能尚未完全适配该版本的 API 或依赖库。
如果 vLLM-OpenAI 服务运行在远程服务器上,或者你在本地运行但遇到连接问题,可能是网络或防火墙限制。
http://localhost:8000 可以被访问。telnet localhost 8000 或 nc -zv localhost 8000 测试端口是否开放。以下是基于 LangChain4j 1.9.1 的示例代码,用于调用 vLLM-OpenAI 服务:
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.model.openai.OpenAiChatModelName;
import dev.langchain4j.service.AiService;
public class VllmOpenAiExample {
public static void main(String[] args) {
// 创建 OpenAI 客户端,指向 vLLM-OpenAI 服务
OpenAiChatModel model = OpenAiChatModel.builder()
.baseUrl("http://localhost:8000")
.modelName(OpenAiChatModelName.GPT_3_5_TURBO)
.build();
String response = model.generate("Hello, how are you?");
System.out.println("Response: " + response);
}
}
注意:
OpenAiChatModelName.GPT_3_5_TURBO只是一个占位符,实际使用中你需要根据 vLLM-OpenAI 支持的模型名称进行调整。
baseUrl 是否指向正确地址| 问题 | 解决方案 |
|------|----------|
| vLLM-OpenAI 服务未启动 | 检查服务状态并重新启动 |
| API 地址配置错误 | 修改 baseUrl 为 http://localhost:8000 |
| 模型路径错误 | 确保启动时指定正确的模型路径 |
| 兼容性问题 | 尝试使用旧版 LangChain4j 或检查文档 |
| 网络或防火墙限制 | 确保端口可访问 |
如你愿意提供具体的错误信息或日志内容,我可以进一步帮助你定位问题根源。
分享 创建了问题
1月31日
创建了问题
1月31日

