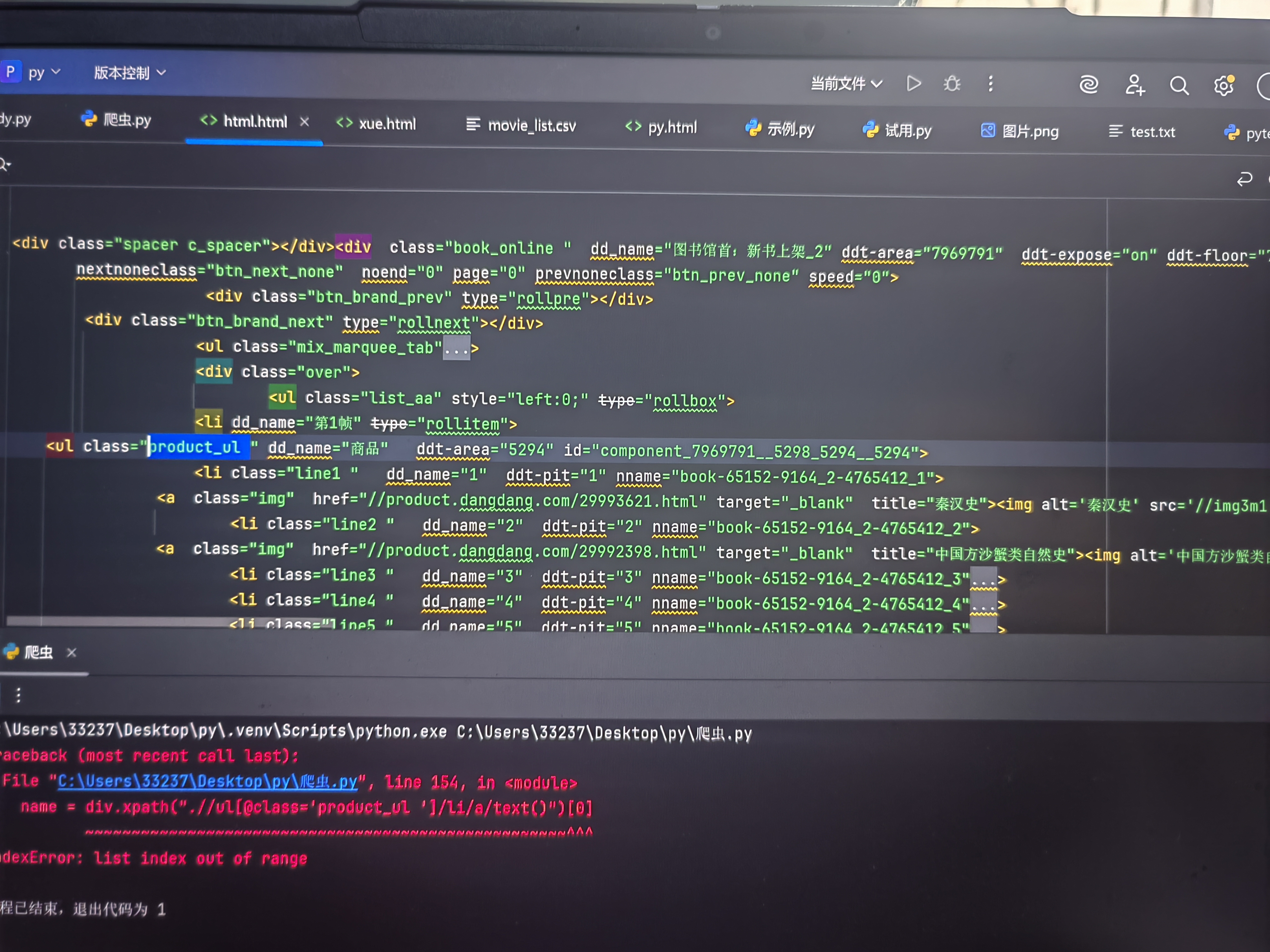
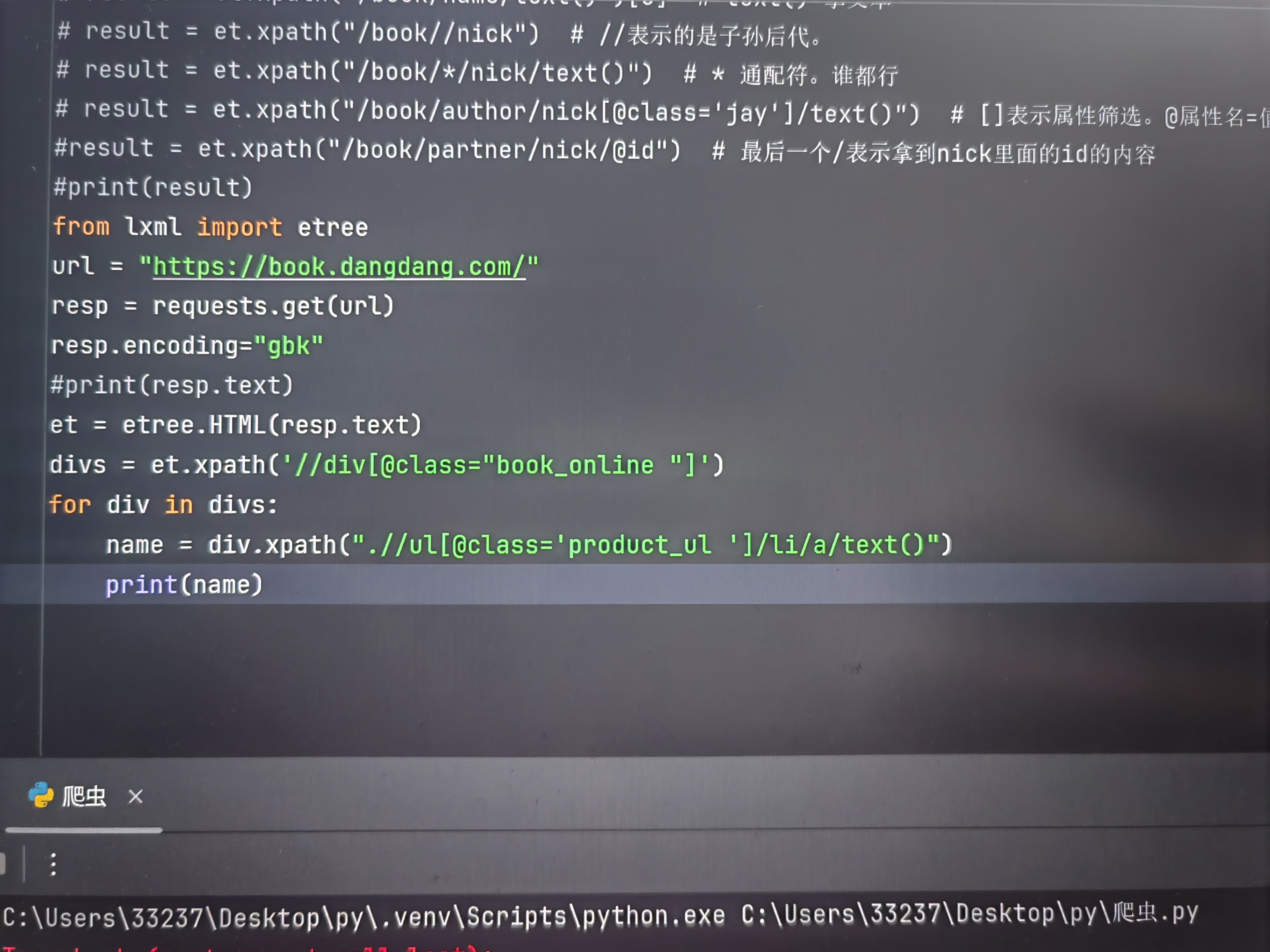
图二是我写的xpath代码,图一是我想爬取的网页的部分源代码,我想要用xpath抓取这里面的书籍信息,也就是源代码中显示的title,但是运行结果总是为空列表,我不知道我是哪一块节点错了,请各位指点一下,谢谢

 分享
分享
下午好🌅🌅🌅
本答案参考通义千问
你提到你的 XPath 代码无法抓取数据,导致结果为空列表。为了更好地帮助你解决问题,我需要你提供以下信息:
不过,根据你提供的描述,我可以先给你一些常见的 XPath 抓取失败的原因和解决方案。
lxml 或 BeautifulSoup)可能无法获取完整内容。请提供你想要抓取的 HTML 片段,比如类似如下结构:
<div class="book-list">
<div class="book-item">
<h2 class="title">《书名一》</h2>
<p class="author">作者一</p>
</div>
<div class="book-item">
<h2 class="title">《书名二》</h2>
<p class="author">作者二</p>
</div>
</div>
例如:
//div[@class='book-item']/h2[@class='title']
或者可能是:
//h2[contains(@class, 'title')]
你可以使用在线 XPath 测试工具(如 https://www.w3schools.com/xml/tryit.asp?filename=tryxpath_ex_basic)来测试你的 XPath 是否能匹配到目标节点。
<h2 class="title"> 的文本内容<div class="book-list">
<div class="book-item">
<h2 class="title">《Python编程从入门到实践》</h2>
<p class="author">Eric Matthes</p>
</div>
</div>
//div[@class='book-list']//h2[@class='title']/text()
from lxml import html
import requests
url = "http://example.com/books"
response = requests.get(url)
tree = html.fromstring(response.content)
# 使用 XPath 提取所有书籍标题
titles = tree.xpath("//div[@class='book-list']//h2[@class='title']/text()")
print(titles)
网页是否是动态加载的?
requests。是否有多个 title 类名?
XPath 是否有拼写错误?
是否在正确的 DOM 节点下?
请提供以下内容,我会帮你分析具体问题:
如果你能提供这些信息,我会给出针对性的修改建议和修改后的 XPath 表达式。
分享 修改了问题
2月3日
创建了问题
2月3日
修改了问题
2月3日
创建了问题
2月3日

