问题遇到的现象和发生背景
为什么我下载了bs4和xlwt,但是还是报错
操作环境、软件版本等信息
PyCharm

为什么我下载了bs4和xlwt,但是还是报错
PyCharm
 分享
分享
晚上好🌙🌙🌙
本答案参考通义千问
你提到已经下载了 bs4 和 xlwt,但仍然遇到报错,这可能涉及多个原因。以下是一些常见的问题及解决方案,帮助你排查和解决这个错误。
安装的包名称或版本不正确
bs4(BeautifulSoup)和 xlwt 是两个不同的库,分别用于网页解析和 Excel 文件写入。beautifulsoup4),或者安装的是旧版本,可能会导致功能异常。未正确导入模块
Python 环境配置错误
依赖冲突或缺失
bs4 依赖 lxml 或 html.parser。代码逻辑错误
在 PyCharm 的终端(Terminal)中运行以下命令:
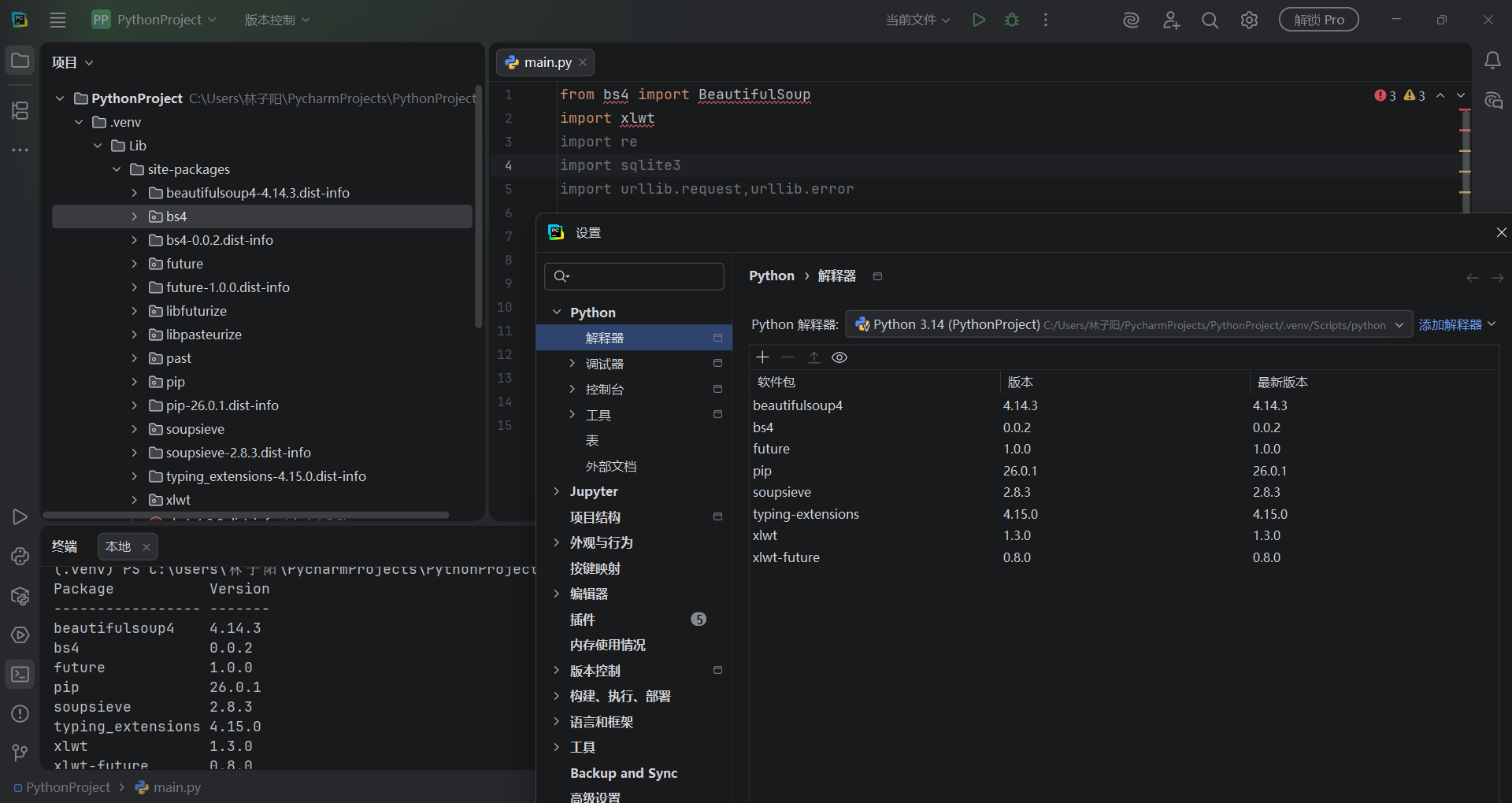
pip show beautifulsoup4
pip show xlwt
注意:
bs4的正确包名是beautifulsoup4,而不是bs4。如果你用pip install bs4,它可能安装了一个不同用途的包。正确的安装方式如下:
pip install beautifulsoup4
pip install lxml # 可选,但推荐安装,提升解析性能
确保你的代码中使用了正确的导入方式:
from bs4 import BeautifulSoup
import xlwt
如果写成:
import bs4
就会出错,因为 bs4 是一个子模块,不是主模块。
在 PyCharm 中,进入:
File > Settings > Project: your_project_name > Python Interpreter
请将完整的错误信息贴出来,这样可以更准确地判断问题所在。
例如:
ModuleNotFoundError: No module named 'bs4'
或
ImportError: cannot import name 'BeautifulSoup' from 'bs4'
这些信息能帮你快速定位问题。
正确安装所需的包
beautifulsoup4 和 lxml(可选):
pip install beautifulsoup4 lxml
xlwt:
pip install xlwt
检查导入语句是否正确
from bs4 import BeautifulSoup
import xlwt
确认 Python 环境配置
查看具体错误信息
更新 pip 和包管理工具
pip install --upgrade pip
以下是使用 BeautifulSoup 和 xlwt 的示例代码:
from bs4 import BeautifulSoup
import xlwt
# 示例 HTML 内容
html = """
<html>
<head><title>测试页面</title></head>
<body>
<p>这是第一个段落。</p>
<p>这是第二个段落。</p>
</body>
</html>
"""
# 使用 BeautifulSoup 解析
soup = BeautifulSoup(html, 'lxml')
paragraphs = soup.find_all('p')
# 创建 Excel 工作簿
workbook = xlwt.Workbook()
sheet = workbook.add_sheet('Sheet1')
# 写入数据
for i, p in enumerate(paragraphs):
sheet.write(i, 0, p.get_text())
# 保存文件
workbook.save('output.xls')
print("Excel 文件已生成!")
| 问题类型 | 原因 | 解决方案 |
|---------|------|----------|
| 包未正确安装 | 使用 pip install bs4 而非 beautifulsoup4 | 使用 pip install beautifulsoup4 |
| 导入错误 | 导入方式错误 | 使用 from bs4 import BeautifulSoup |
| 环境配置错误 | PyCharm 使用了错误的解释器 | 检查并设置正确的 Python 解释器 |
| 依赖缺失 | 缺少 lxml 或其他依赖 | 安装 lxml 提升性能 |
如果你能提供具体的错误信息,我可以进一步帮你定位问题。欢迎继续提问!
分享 创建了问题
2月6日
创建了问题
2月6日

