您好,我现在处于学习python爬虫的初级阶段。
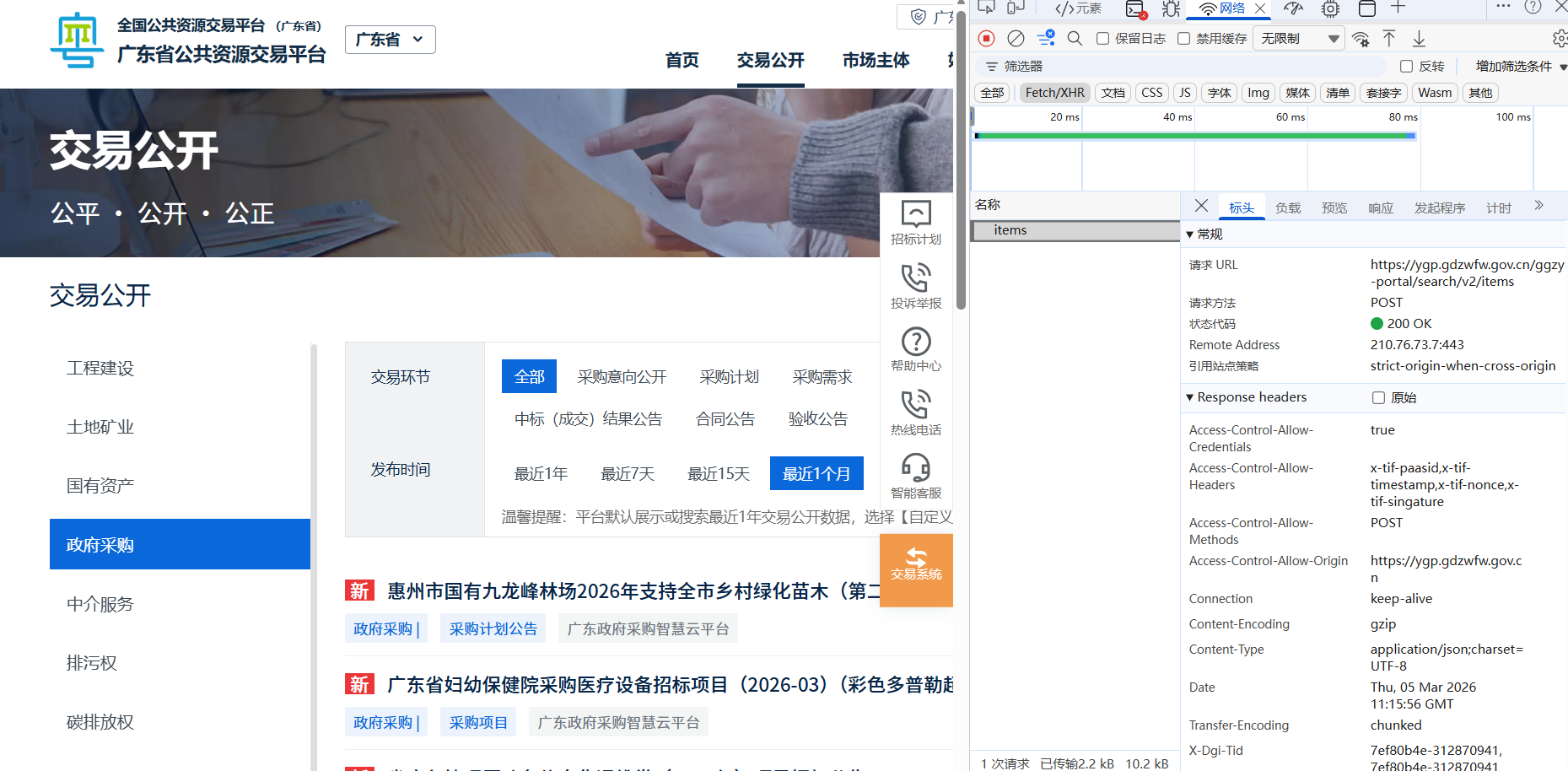
想请教一下,我最近尝试从https://ygp.gdzwfw.gov.cn/#/44/jygg,获取栏目“政府采购”中检索近1个月全部公告。
但是我一直苦于找不到获取数据的接口。从标头中获取的请求url也找不到,不知道有什么解决的方法。

您好,我现在处于学习python爬虫的初级阶段。
想请教一下,我最近尝试从https://ygp.gdzwfw.gov.cn/#/44/jygg,获取栏目“政府采购”中检索近1个月全部公告。
但是我一直苦于找不到获取数据的接口。从标头中获取的请求url也找不到,不知道有什么解决的方法。
 分享
分享
我来帮你解决这个政府采购网站的爬虫问题,这个网站是广东省政府采购网的页面,属于动态加载的网站,我们可以通过分析接口来获取数据,以下是完整的解决方案:
list,可以找到获取公告列表的接口:https://ygp.gdzwfw.gov.cn/ygp/api/notice/queryNoticeListimport requests
import json
from datetime import datetime, timedelta
# 计算近1个月的时间范围
end_date = datetime.now().strftime("%Y-%m-%d")
start_date = (datetime.now() - timedelta(days=30)).strftime("%Y-%m-%d")
# 请求头,模拟浏览器访问
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
"Content-Type": "application/json",
"Referer": "https://ygp.gdzwfw.gov.cn/#/44/jygg",
"Origin": "https://ygp.gdzwfw.gov.cn"
}
# 请求URL
url = "https://ygp.gdzwfw.gov.cn/ygp/api/notice/queryNoticeList"
# 初始化参数
page_num = 1
page_size = 15
all_data = []
while True:
# 构造请求体
payload = {
"pageNum": page_num,
"pageSize": page_size,
"noticeType": "01", # 政府采购公告类型
"noticeRegionCode": "44", # 广东省
"startDate": start_date,
"endDate": end_date,
"keyWord": "", # 搜索关键词,这里为空表示全部
"purchaseWay": "",
"noticeStatus": ""
}
try:
# 发送POST请求
response = requests.post(url, headers=headers, data=json.dumps(payload))
response.raise_for_status() # 检查请求是否成功
# 解析响应数据
result = response.json()
if result["code"] == 200 and result["data"]["records"]:
records = result["data"]["records"]
all_data.extend(records)
print(f"第{page_num}页,获取到{len(records)}条数据")
# 检查是否还有下一页
total_pages = result["data"]["pages"]
if page_num >= total_pages:
break
page_num += 1
else:
break
except Exception as e:
print(f"请求出错:{e}")
break
# 保存数据到JSON文件
output_file = f"政府采购公告_{start_date}_至_{end_date}.json"
with open(output_file, "w", encoding="utf-8") as f:
json.dump(all_data, f, ensure_ascii=False, indent=4)
print(f"数据获取完成,共{len(all_data)}条,已保存到{output_file}")
noticeType:公告类型,01是政府采购公告,其他类型可以通过开发者工具查看noticeRegionCode:地区代码,44代表广东省,其他地区可以修改pageSize:每页数量,最大可以设置为50如果需要获取公告详情,可以进一步爬取详情页面:
# 添加获取详情的函数
def get_notice_detail(notice_id):
detail_url = f"https://ygp.gdzwfw.gov.cn/ygp/api/notice/getNoticeDetailById/{notice_id}"
try:
response = requests.get(detail_url, headers=headers)
response.raise_for_status()
return response.json()["data"]
except Exception as e:
print(f"获取详情出错:{e}")
return None
# 在获取列表后,遍历获取详情
for item in all_data:
detail = get_notice_detail(item["noticeId"])
if detail:
item["detail"] = detail
robots.txt协议如果运行过程中遇到问题,可以检查:
这个方案应该能帮你成功获取到近1个月的全部政府采购公告数据。
分享 创建了问题
3月5日
创建了问题
3月5日


