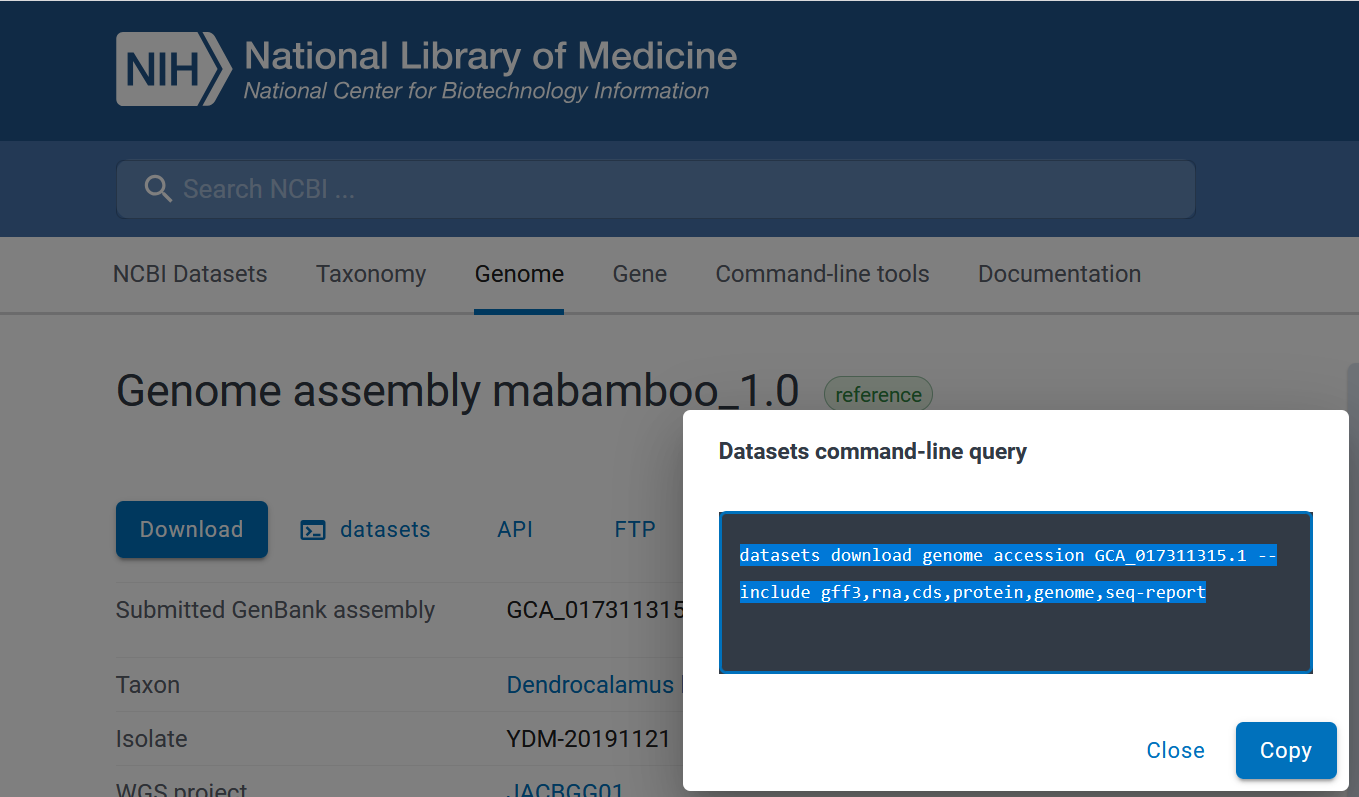
在网页版NCBI的download里边没有gff3和gtf文件。我想下载gff3文件

 分享
分享
下午好🌅🌅🌅
本答案参考通义千问
在NCBI网站上,datasets 是一个用于下载基因组数据的工具,它提供了多种格式的文件,包括 FASTA、GFF3、GTF、BED、VCF 等。如果你在网页版 NCBI 的 "Download" 页面找不到 GFF3 或 GTF 文件,可能是你没有正确使用 datasets 工具。
以下是详细步骤和解决方案:
打开浏览器,访问以下链接:
Escherichia coli)。Reference genome 或 Genome assembly)。点击你选择的基因组进入详情页,可以看到该基因组的各种信息和可用文件。
有时候某些基因组可能不提供 GFF3 或 GTF 文件,这时候你可以尝试以下方法:
获取基因组 ID
txid123456)。使用 datasets 命令行工具
curl -L https://ftp.ncbi.nlm.nih.gov/blast/exec/ncbi-tools.tar.gz | tar xzf -
cd ncbi-tools
./configure
make
sudo make install
使用 API 请求 GFF3 文件
示例请求(以 Escherichia coli 为例):
GET https://api.ncbi.nlm.nih.gov/datasets/v1/genome/accession/GCF_000005845.2/gff3
可以使用 curl 命令下载:
curl -o output.gff3 https://api.ncbi.nlm.nih.gov/datasets/v1/genome/accession/GCF_000005845.2/gff3
import requests
# 替换为你的基因组 ID
genome_accession = "GCF_000005845.2"
url = f"https://api.ncbi.nlm.nih.gov/datasets/v1/genome/accession/{genome_accession}/gff3"
response = requests.get(url)
if response.status_code == 200:
with open("output.gff3", "w") as f:
f.write(response.text)
print("GFF3 文件已成功下载!")
else:
print(f"下载失败,状态码:{response.status_code}")
如果你能提供具体的基因组 ID 或物种名称,我可以帮你进一步定位下载链接。
分享 系统已结题
3月26日
系统已结题
3月26日 已采纳回答
3月18日
修改了问题
3月10日
创建了问题
3月10日
已采纳回答
3月18日
修改了问题
3月10日
创建了问题
3月10日


