像这样的下拉框属性怎么进行选择?

python+selenium怎么点击ul中的li下拉框

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

2条回答 默认 最新
 qq_15256969 2021-08-09 14:28关注
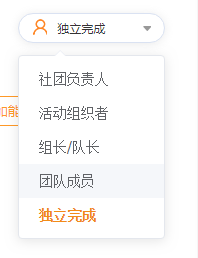
qq_15256969 2021-08-09 14:28关注我也碰到了同样的问题,批量的选不好写,只会单个点击:
点击选择第5个标签:独立完成
driver.find_element(By.XPATH, "//div/div/ul/li[5][@class='el-select-dropdown-menu_item']").click()
评论 打赏解决 6无用举报 分享
- 2020-12-06 06:27weixin_39605326的博客 最近在尝试给自己负责的模块写UI自动化的Demo登录及切换页面比较顺利但是遇到下拉框的...是ul下包裹100+li的形式先说一下错误路径:(1)先定位到产品名称字段,然后通过send_key()把想要录入的值输入结果:前端设定录...
- 2021-09-21 19:53阿阿臻的博客 from selenium.webdriver.common.action_chains import ActionChains # 打开浏览器并加载项目地址-->携程注册页面 driver = webdriver.Chrome() driver.get("https://passport.ctrip.com/use.
- 2021-10-24 18:55梦里有阳光的博客 selenium操作页面下拉框,...另一种是非select类下拉框,比如ul-li标签下拉框。针对select标签的下拉框,selenium提供了一个select类;针对非select标签实现的下拉框,可以通过模拟鼠标点击的方式实现操作。 ...
- 2022-06-04 00:50Buaixiao的博客 Python+Selenium PO模式Web自动化测试实战
- 2024-08-16 09:56HW_Phoenix_N的博客 介绍Web自动化-Python+selenium+pytest的基础用法
- 2025-07-20 17:25行家说竞赛的博客 号输错有很多种情况),验证一方面比较复杂,需要编写大量的脚本,另一方面自动化脚本本身比较脆弱,2、一个脚本脚本只验证一个功能点,不要试图...6、在整个脚本中只对验证点进行验证,不要对整个脚本每一步都做验证。
- 2020-01-10 11:14Missshi的博客 用selenium IDE或者Firebug定位出来的下拉框的元素,显示在如下图的div/ul/li标签下,运行测试用例一直显示定位不到元素 但是其实往下看是可以看到有select标签的,但是直接用工具定位并不能定位到,所以要自己...
- 2024-11-13 14:41Cser__的博客 'file')[0] #send_keys 方法可以模拟用户在文件选择器中选择文件的操作,将文件路径(由变量 path 提供)输入到文件上传控件中 #r"{}".format(path) 的格式化语句确保路径以原始字符串的形式传入,避免转义字符影响 ...
- 2022-04-12 14:12小菜鸡学嵌入式的博客 例如:python 自动化----1、元素定位+下拉列表的定位 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录八大元素和下拉列表的定位前言一、八大元素定位1.环境的安装和注意点id元素定位...
- 2022-12-18 17:07檬柠wan的博客 Python Selenium是Selenium WebDriver的Python语言封装,为Python开发者提供了一个方便易用的自动化测试库。它支持多种浏览器(如Chrome、Firefox、Edge等)以及多个操作系统,可以模拟用户在浏览器中的各种行为,...
- 没有解决我的问题, 去提问
