
应用SVR对负荷数据进行回归分析,测试集出来的数为一条直线?
import numpy as np
from sklearn.svm import SVR
import pandas as pd
import matplotlib.pyplot as plt
import xlrd
# 打开指定路径中的xls文件,得到book对象
xls_file = "bb.xls"
#打开指定文件
book = xlrd.open_workbook(xls_file)
# 通过sheet索引获得sheet对象
sheet1 = book.sheet_by_index(0)
# # 获得指定索引的sheet名
# sheet1_name = book.sheet_names()[0]
# print(sheet1_name)
# # 通过sheet名字获得sheet对象
# sheet1 = book.sheet_by_name(sheet1_name)
# 获得行数和列数
# 总行数
nrows = sheet1.nrows
#总列数
ncols = sheet1.ncols
# 遍历打印表中的内容
row_list=[]
for i in range(nrows):
for j in range(ncols):
cell_value = sheet1.cell_value(i, j)
row_list.append (cell_value)#append函数的用处为往一个空矩阵添加元素
x=range(1,156) #绘制横坐标时间数据
#提取Excel表里的数据cell_value即是y值
x1=np.array(x)
X=x1.reshape((len(x1),1))##reshape用于转置
y=np.array(row_list)
X_train=np.array(X[0:123]) #训练集124
X_test=np.array(X[124:154])
y_train=np.array(y[0:123]) #测试集31
y_test=np.array(y[124:154])
svr_rbf=SVR(kernel='rbf',C=1e3,gamma=0.1) #使用 rbf核进行拟合
clf=svr_rbf.fit(X_train,y_train) #训练得到分类器#中括号的用途
y_rbf=clf.predict(X) #预测的输出
ax=plt.subplot(111)
ax.scatter(X_train,y_train,c='r',label='train') #训练集真实值的散点图
ax.scatter(X_test,y_test,c='g',label='test') #测试集真实值的散点图
ax.plot(X,y_rbf,c='b',label='RBF model') #训练集的拟合结果 #测试集的结果为一常值,是因为数据集未进行归一化处理
plt.xlabel('day')
plt.ylabel('target')
plt.title('Support Vector Regression')
plt.legend()
plt.show()
程序运行结果如下:
```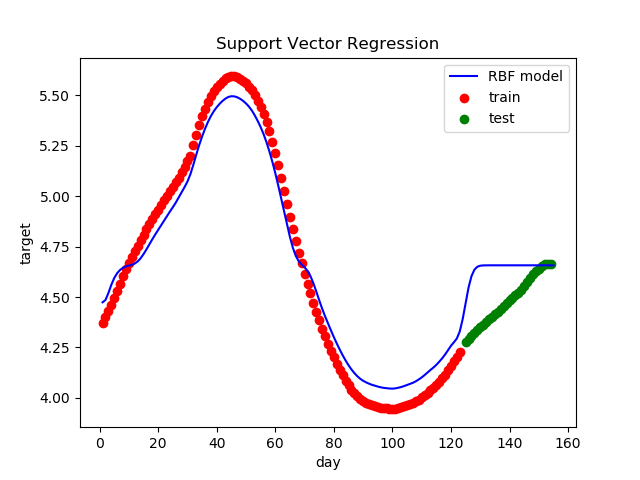
请各位大佬指点!!






