下午好🌅🌅🌅
本答案参考通义千问
你提出的问题非常具有代表性,尤其是在贝叶斯推断中遇到参数强相关性导致后验分布图出现“脊”状结构(即没有明显峰值)时,确实容易让人困惑。下面我将从以下几个方面详细分析你的问题,并提供解决方案。
一、问题核心分析
1. 后验分布呈现“脊”状的原因
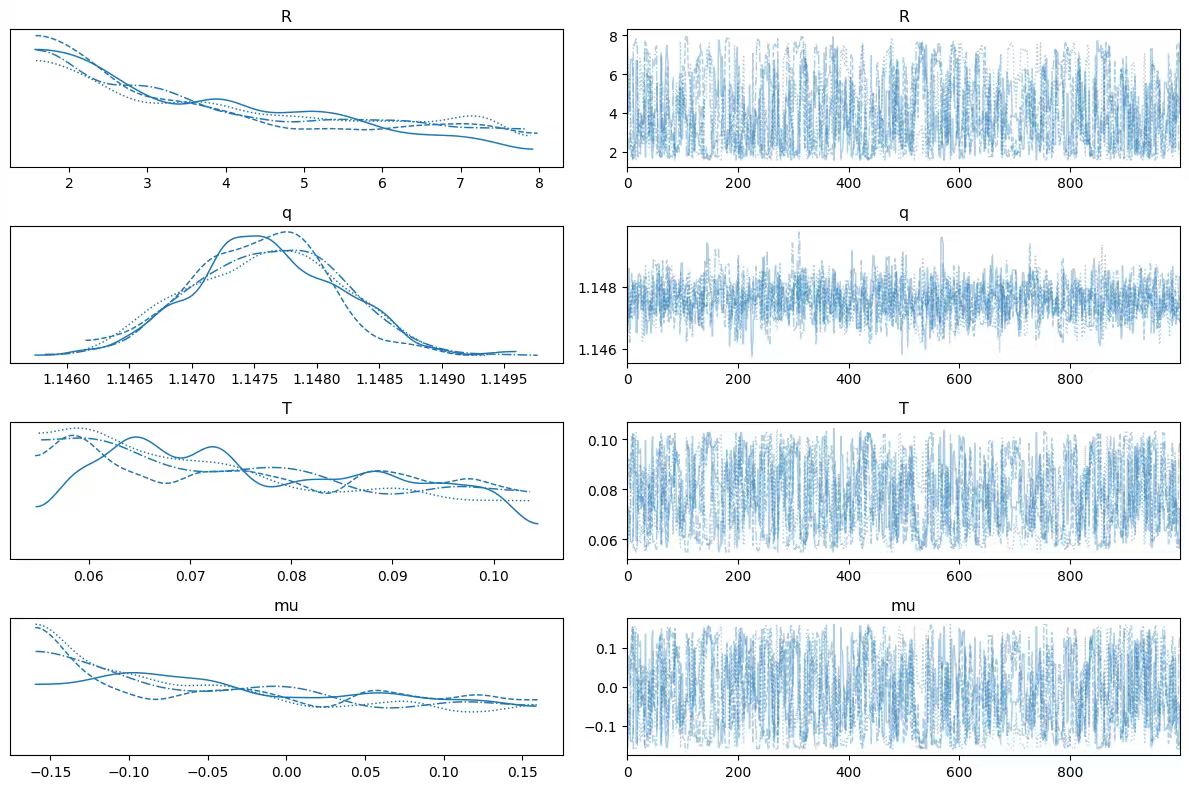
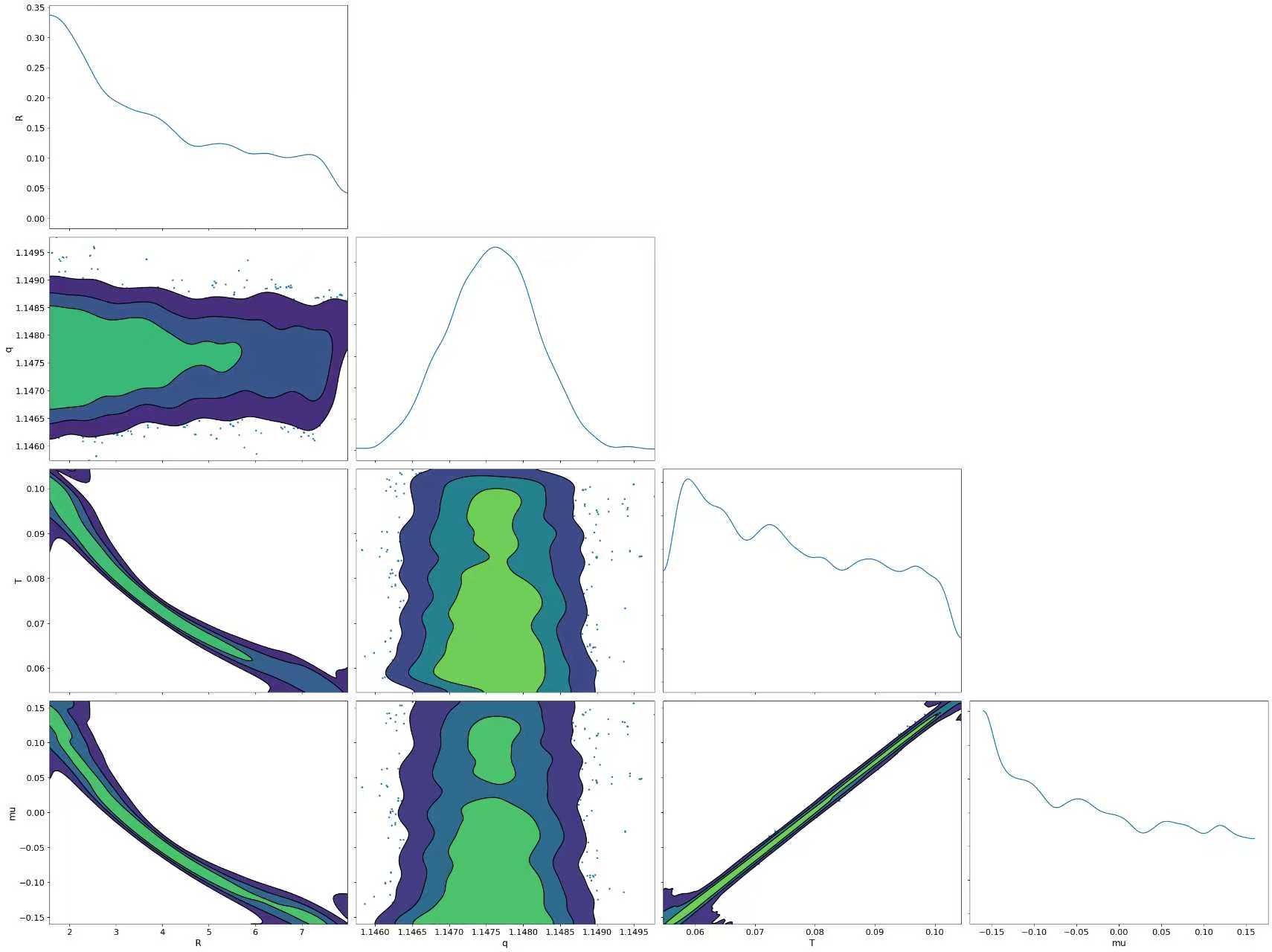
你提到的后验分布图“几乎都没有峰值是一条脊”,这通常意味着以下几种可能性:
- 参数之间存在强相关性:这是最常见的情况。当多个参数在模型中高度相关时,它们的联合后验分布会呈现出一个“脊”状结构,而不是一个明显的多维高斯分布。
- 先验设置不合理或过于宽松:如果先验范围太宽,可能导致采样器在参数空间中难以找到有效的区域,从而形成“脊”状分布。
- 似然函数对某些参数不敏感:如果某些参数在模型中对观测数据的影响很小,那么它们的后验分布可能没有显著的峰值。
2. 关于 r-hat 收敛性
你提到 r-hat 显示收敛,这说明 MCMC 采样器已经达到了某种平稳状态,但并不意味着后验分布一定是“理想”的。r-hat 只是衡量链间一致性的指标,不能完全反映后验分布的形状是否合理。
二、关于对方提出的“无先验抽样”方法的评价
你提到的另一种方法是:
“不需要设置先验,直接在先验范围内取 randomreal,然后按照 Metropolis 抽样对函数 EXP[-(y - yexp)² / (1000δ²)] 抽样。”
1. 这种方法的问题
- 缺乏先验约束:贝叶斯推断的核心在于结合先验和似然函数,而这种方法忽略了先验信息,仅依赖似然函数进行采样。这相当于在做最大似然估计(MLE),而非贝叶斯推断。
- 不确定性无法正确量化:由于没有先验,后验分布实际上就是似然函数的缩放形式,因此无法准确反映参数的不确定性。
- 无法处理参数相关性:这种做法在参数高度相关时更容易失败,因为似然函数可能无法有效引导采样器。
2. 为什么他得到的后验分布有峰值?
他可能通过调整似然函数的权重(如分母较大),使得似然函数更“尖锐”,从而让采样器“看到”一个“中心值”。但这只是人为构造的结果,并不能代表真实后验分布,也不具备统计意义。
三、如何应对当前的后验分布图?
1. 建议的解决方案
✅ 解决方案 1:检查参数之间的相关性
- 使用
pm.traceplot() 或 pm.pairplot() 查看参数之间的相关性。 - 如果发现参数之间存在强相关性,可以尝试:
- 重新定义参数:例如使用非线性变换(如对数、归一化等)来降低相关性。
- 引入辅助变量:有时引入中间变量可以帮助解耦参数之间的关系。
✅ 解决方案 2:改进先验设置
- 缩小先验范围:如果你认为某些参数的取值范围较窄,可以适当减小先验的方差。
- 使用
pm.Normal、pm.Uniform 等更合理的先验分布,而不是随意设定。
✅ 解决方案 3:调整采样器配置
- 尝试使用
NUTS 而不是 Metropolis,因为 NUTS 更适合高维空间中的采样。 - 增加
tune 和 draws 的数量,确保充分探索后验分布。
✅ 解决方案 4:可视化与诊断
- 使用
pm.summary() 检查每个参数的均值、标准差、hpd 区间等。 - 使用
pm.plot_posterior() 查看每个参数的后验分布是否合理。
四、是否应该用平均值 ± 标准差作为结果?
✅ 结论:不推荐直接使用平均值 ± 标准差作为最终结果
原因如下:
- 当后验分布呈“脊”状时,均值和标准差可能不具备实际意义,因为它们可能无法反映真正的分布形态。
- 更可靠的做法是:
- 使用 HPD(Highest Posterior Density)区间 来表示不确定性。
- 使用后验样本的分位数(如 2.5% 和 97.5% 分位点)来表示置信区间。
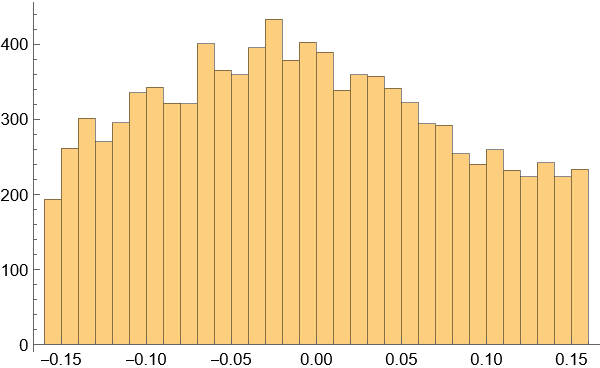
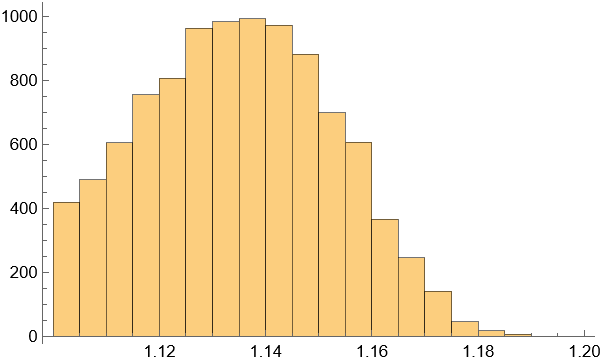
- 绘制后验分布直方图/密度图 来直观展示分布形态。
五、代码示例(Pymc3)
import pymc3 as pm
import numpy as np
# 示例数据
data = np.random.normal(loc=0, scale=1, size=100)
yexp = data # 假设预测值等于观测值
with pm.Model() as model:
# 定义参数先验
mu = pm.Normal('mu', mu=0, sigma=1)
sigma = pm.HalfNormal('sigma', sigma=1)
delta = pm.HalfNormal('delta', sigma=1)
alpha = pm.Normal('alpha', mu=0, sigma=1)
# 定义似然函数
likelihood = pm.Normal('likelihood', mu=mu + alpha * data, sigma=sigma, observed=yexp)
# 采样
trace = pm.sample(
draws=2000,
tune=1000,
chains=4,
step=pm.NUTS()
)
# 后验分析
pm.summary(trace)
pm.plot_posterior(trace, var_names=['mu', 'sigma', 'delta', 'alpha'])
六、总结
| 问题 | 解决方案 |
|------|----------|
| 后验分布呈“脊”状 | 检查参数相关性,调整先验或参数定义 |
| r-hat 收敛但分布异常 | 需要结合后验分布图判断是否真正收敛 |
| 对方提出的方法 | 不推荐,缺乏贝叶斯理论基础,不可靠 |
| 是否用均值 ± 标准差 | 不推荐,应使用 HPD 区间或分位数 |
如果你能提供具体的后验分布图或部分代码,我可以进一步帮助你分析具体问题。希望以上内容对你有所帮助!