
最近在跑deeplabv1,在测试代码的时候,跑通了训练程序,但是用训练好的模型进行与测试却发现相同的图片预测的结果不一样??请问有大神知道怎么回事吗?
用的是saver.restore()方法载入模型。代码如下:
def main():
"""Create the model and start the inference process."""
args = get_arguments()
# Prepare image.
img = tf.image.decode_jpeg(tf.read_file(args.img_path), channels=3)
# Convert RGB to BGR.
img_r, img_g, img_b = tf.split(value=img, num_or_size_splits=3, axis=2)
img = tf.cast(tf.concat(axis=2, values=[img_b, img_g, img_r]), dtype=tf.float32)
# Extract mean.
img -= IMG_MEAN
# Create network.
net = DeepLabLFOVModel()
# Which variables to load.
trainable = tf.trainable_variables()
# Predictions.
pred = net.preds(tf.expand_dims(img, dim=0))
# Set up TF session and initialize variables.
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
#init = tf.global_variables_initializer()
sess.run(tf.global_variables_initializer())
# Load weights.
saver = tf.train.Saver(var_list=trainable)
load(saver, sess, args.model_weights)
# Perform inference.
preds = sess.run([pred])
print(preds)
if not os.path.exists(args.save_dir):
os.makedirs(args.save_dir)
msk = decode_labels(np.array(preds)[0, 0, :, :, 0])
im = Image.fromarray(msk)
im.save(args.save_dir + 'mask1.png')
print('The output file has been saved to {}'.format(
args.save_dir + 'mask.png'))
if __name__ == '__main__':
main()
其中load是
def load(saver, sess, ckpt_path):
'''Load trained weights.
Args:
saver: TensorFlow saver object.
sess: TensorFlow session.
ckpt_path: path to checkpoint file with parameters.
'''
ckpt = tf.train.get_checkpoint_state(ckpt_path)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
print("Restored model parameters from {}".format(ckpt_path))
DeepLabLFOVMode类如下:
class DeepLabLFOVModel(object):
"""DeepLab-LargeFOV model with atrous convolution and bilinear upsampling.
This class implements a multi-layer convolutional neural network for semantic image segmentation task.
This is the same as the model described in this paper: https://arxiv.org/abs/1412.7062 - please look
there for details.
"""
def __init__(self, weights_path=None):
"""Create the model.
Args:
weights_path: the path to the cpkt file with dictionary of weights from .caffemodel.
"""
self.variables = self._create_variables(weights_path)
def _create_variables(self, weights_path):
"""Create all variables used by the network.
This allows to share them between multiple calls
to the loss function.
Args:
weights_path: the path to the ckpt file with dictionary of weights from .caffemodel.
If none, initialise all variables randomly.
Returns:
A dictionary with all variables.
"""
var = list()
index = 0
if weights_path is not None:
with open(weights_path, "rb") as f:
weights = cPickle.load(f) # Load pre-trained weights.
for name, shape in net_skeleton:
var.append(tf.Variable(weights[name],
name=name))
del weights
else:
# Initialise all weights randomly with the Xavier scheme,
# and
# all biases to 0's.
for name, shape in net_skeleton:
if "/w" in name: # Weight filter.
w = create_variable(name, list(shape))
var.append(w)
else:
b = create_bias_variable(name, list(shape))
var.append(b)
return var
def _create_network(self, input_batch, keep_prob):
"""Construct DeepLab-LargeFOV network.
Args:
input_batch: batch of pre-processed images.
keep_prob: probability of keeping neurons intact.
Returns:
A downsampled segmentation mask.
"""
current = input_batch
v_idx = 0 # Index variable.
# Last block is the classification layer.
for b_idx in xrange(len(dilations) - 1):
for l_idx, dilation in enumerate(dilations[b_idx]):
w = self.variables[v_idx * 2]
b = self.variables[v_idx * 2 + 1]
if dilation == 1:
conv = tf.nn.conv2d(current, w, strides=[
1, 1, 1, 1], padding='SAME')
else:
conv = tf.nn.atrous_conv2d(
current, w, dilation, padding='SAME')
current = tf.nn.relu(tf.nn.bias_add(conv, b))
v_idx += 1
# Optional pooling and dropout after each block.
if b_idx < 3:
current = tf.nn.max_pool(current,
ksize=[1, ks, ks, 1],
strides=[1, 2, 2, 1],
padding='SAME')
elif b_idx == 3:
current = tf.nn.max_pool(current,
ksize=[1, ks, ks, 1],
strides=[1, 1, 1, 1],
padding='SAME')
elif b_idx == 4:
current = tf.nn.max_pool(current,
ksize=[1, ks, ks, 1],
strides=[1, 1, 1, 1],
padding='SAME')
current = tf.nn.avg_pool(current,
ksize=[1, ks, ks, 1],
strides=[1, 1, 1, 1],
padding='SAME')
elif b_idx <= 6:
current = tf.nn.dropout(current, keep_prob=keep_prob)
# Classification layer; no ReLU.
# w = self.variables[v_idx * 2]
w = create_variable(name='w', shape=[1, 1, 1024, n_classes])
# b = self.variables[v_idx * 2 + 1]
b = create_bias_variable(name='b', shape=[n_classes])
conv = tf.nn.conv2d(current, w, strides=[1, 1, 1, 1], padding='SAME')
current = tf.nn.bias_add(conv, b)
return current
def prepare_label(self, input_batch, new_size):
"""Resize masks and perform one-hot encoding.
Args:
input_batch: input tensor of shape [batch_size H W 1].
new_size: a tensor with new height and width.
Returns:
Outputs a tensor of shape [batch_size h w 18]
with last dimension comprised of 0's and 1's only.
"""
with tf.name_scope('label_encode'):
# As labels are integer numbers, need to use NN interp.
input_batch = tf.image.resize_nearest_neighbor(
input_batch, new_size)
# Reducing the channel dimension.
input_batch = tf.squeeze(input_batch, squeeze_dims=[3])
input_batch = tf.one_hot(input_batch, depth=n_classes)
return input_batch
def preds(self, input_batch):
"""Create the network and run inference on the input batch.
Args:
input_batch: batch of pre-processed images.
Returns:
Argmax over the predictions of the network of the same shape as the input.
"""
raw_output = self._create_network(
tf.cast(input_batch, tf.float32), keep_prob=tf.constant(1.0))
raw_output = tf.image.resize_bilinear(
raw_output, tf.shape(input_batch)[1:3, ])
raw_output = tf.argmax(raw_output, dimension=3)
raw_output = tf.expand_dims(raw_output, dim=3) # Create 4D-tensor.
return tf.cast(raw_output, tf.uint8)
def loss(self, img_batch, label_batch):
"""Create the network, run inference on the input batch and compute loss.
Args:
input_batch: batch of pre-processed images.
Returns:
Pixel-wise softmax loss.
"""
raw_output = self._create_network(
tf.cast(img_batch, tf.float32), keep_prob=tf.constant(0.5))
prediction = tf.reshape(raw_output, [-1, n_classes])
# Need to resize labels and convert using one-hot encoding.
label_batch = self.prepare_label(
label_batch, tf.stack(raw_output.get_shape()[1:3]))
gt = tf.reshape(label_batch, [-1, n_classes])
# Pixel-wise softmax loss.
loss = tf.nn.softmax_cross_entropy_with_logits(logits=prediction, labels=gt)
reduced_loss = tf.reduce_mean(loss)
return reduced_loss
按理说载入模型应该没有问题,可是不知道为什么结果却不一样?
图片:
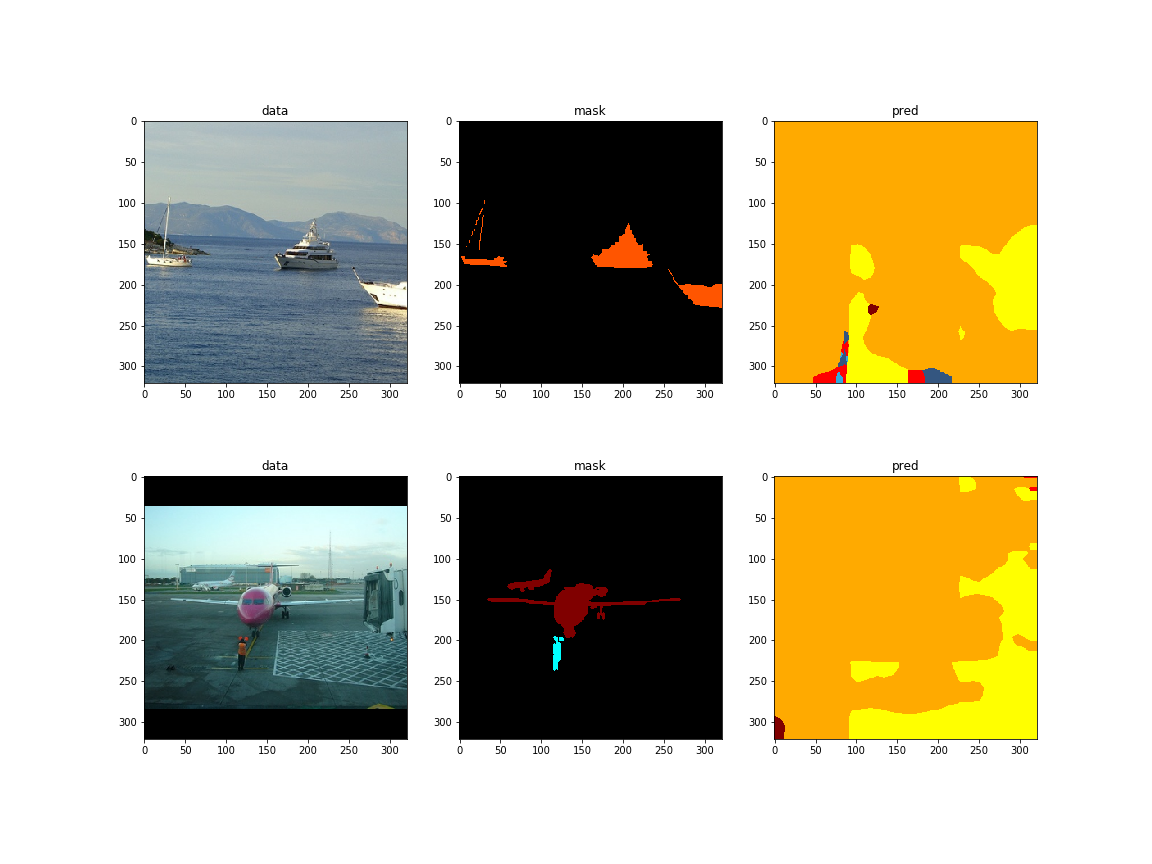
预测的结果:

两次结果不一样,与保存的模型算出来的结果也不一样。
我用的是GitHub上这个人的代码:
https://github.com/minar09/DeepLab-LFOV-TensorFlow
急急急,请问有大神知道吗???




