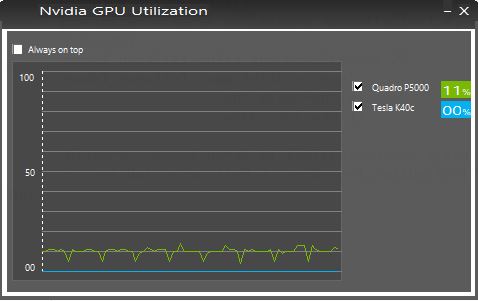
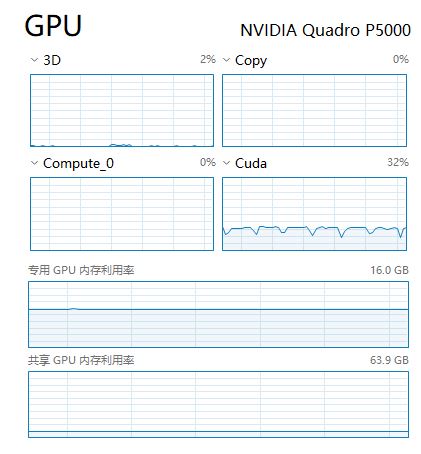
已经按multi_gpu_model进行了设置
但是运行的时候还是只能调用一个GPU,另一张计算卡完全没用,是什么原因呢?
from keras.utils import multi_gpu_model
...
model = build_model()
optimizer = keras.optimizers.Adadelta(lr=1.0, rho=0.95, epsilon=1e-06)
model_parallel=multi_gpu_model(model,2)
model_parallel.compile(loss='mse',
optimizer=optimizer,
metrics=['mae'])
...
history = model_parallel.fit(train_data, y_train, epochs=EPOCHS, validation_split=0.2, verbose=1,callbacks=[PrintDot()])