尚硅谷电商6.0安装spark配置 Hive on Spark使用可见的纯净版的,安装教程配置启动hive,创建表执行insert into table student values(1,'abc');报30041错误
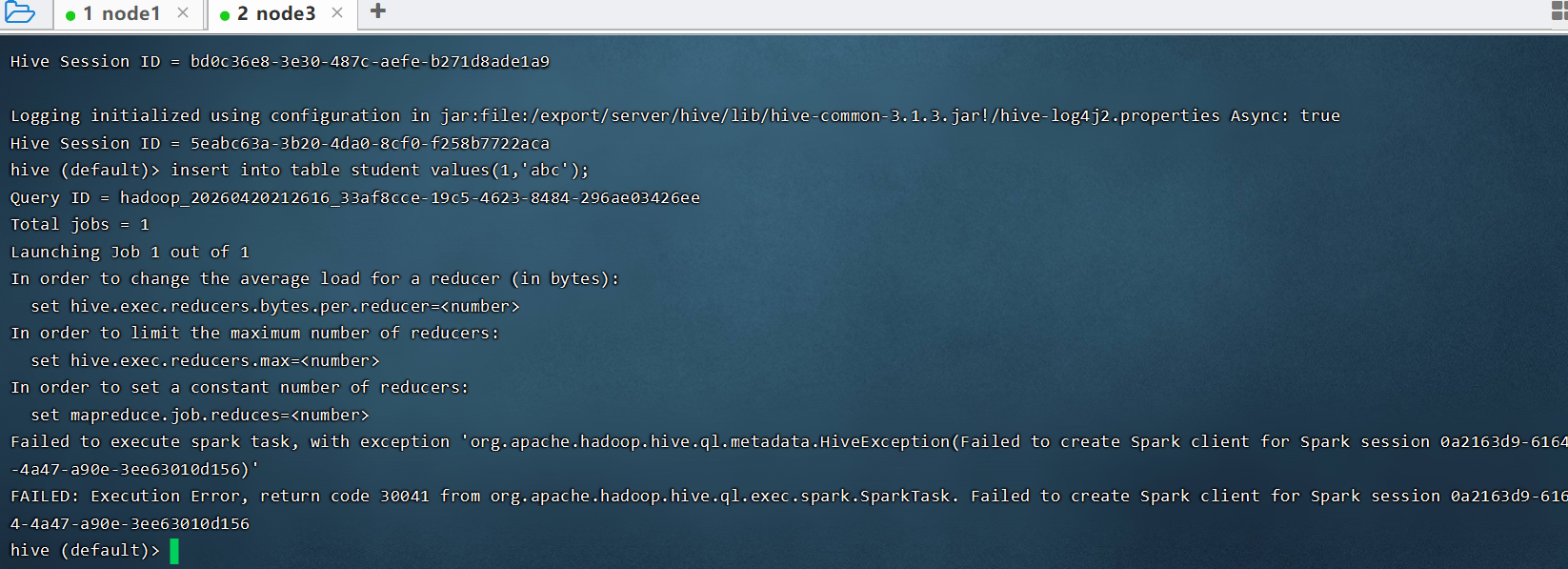
修改引擎spark为MR就可以插入成功,根据豆包说的,修改参数、配置,jar包,重新安装hive,最后还是报这个错误,不兼容,但是课件提供的是他们编译过的安装包,不知道哪里我配置错误,怎么排查呢

尚硅谷电商6.0安装spark配置 Hive on Spark使用可见的纯净版的,安装教程配置启动hive,创建表执行insert into table student values(1,'abc');报30041错误
修改引擎spark为MR就可以插入成功,根据豆包说的,修改参数、配置,jar包,重新安装hive,最后还是报这个错误,不兼容,但是课件提供的是他们编译过的安装包,不知道哪里我配置错误,怎么排查呢
 分享
分享
晚上好🌙🌙🌙
本答案参考通义千问
你提到的 “Hive on Spark 配置” 是一个常见的大数据开发场景,尤其是在使用 尚硅谷电商6.0 的项目中。你遇到的问题是:在 Hive 中执行 INSERT INTO TABLE student VALUES (1, 'abc') 时出现错误 30041,而将引擎切换为 MapReduce(MR)后可以正常插入。
这个问题通常与 Hive 和 Spark 的版本兼容性、配置文件设置、以及依赖库缺失或冲突 有关。下面我将详细分析可能的原因,并提供 排查步骤和解决方案。
错误代码 30041 通常是 Hive 在使用 Spark 作为执行引擎时,无法正确启动 Spark 作业,可能的错误原因包括:
| 组件 | 推荐版本 | |------|----------| | Hadoop | 2.7.x 或 3.x | | Hive | 2.3.x 或 3.x | | Spark | 2.4.x 或 3.0.x | | Java | JDK 8 或 11 |
注意:不同版本之间可能存在兼容问题,建议使用官方测试过的组合。
hive-site.xml确保以下配置项已正确设置:
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<property>
<name>spark.master</name>
<value>local[*]</value> <!-- 或 yarn -->
</property>
<property>
<name>spark.submit.deployMode</name>
<value>client</value>
</property>
<property>
<name>spark.app.name</name>
<value>HiveOnSpark</value>
</property>
<property>
<name>spark.home</name>
<value>/path/to/spark</value>
</property>
<property>
<name>hive.spark.client.maxRetries</name>
<value>5</value>
</property>
注意: 如果你使用的是 YARN 模式,请确保
spark.master设置为yarn,并且spark.yarn.maxAppAttempts等参数也需合理配置。
spark-defaults.conf确保包含以下内容:
spark.driver.extraClassPath /path/to/hive/lib/*
spark.executor.extraClassPath /path/to/hive/lib/*
spark.sql.hive.metastore.version 2.3.7
spark.sql.hive.metastore.jars /path/to/hive/lib/*
确保 Hive 安装目录下的 lib 文件夹中包含以下 Spark 相关的 JAR 包:
hive-exec-*.jarspark-core_2.12-*.jarspark-sql-kafka-0-10_2.12-*.jar(如果用到 Kafka)hive-hcatalog-core-*.jarhive-metastore-*.jar重点: 一定要使用 与 Spark 版本匹配的 Scala 版本,例如 Spark 2.4.x 通常使用 Scala 2.11,Spark 3.x 使用 Scala 2.12。
执行 ./bin/spark-submit --version 查看是否能正确识别 Spark。
尝试运行一个简单的 Spark 任务,如:
./bin/spark-submit --master local[*] --class org.apache.spark.SparkSubmit --conf spark.driver.extraClassPath=/path/to/hive/lib/* /path/to/hive/lib/hive-exec-*.jar
/var/log/hive/ 或 Hive 安装目录下的 logs/ 文件夹)。hive.loghiveserver2.logspark.log执行以下命令查看当前 Hive 的执行引擎:
SET hive.execution.engine;
应显示为 spark。
hive --service metastore 启动元数据服务hive-site.xml 示例:<configuration>
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<property>
<name>spark.master</name>
<value>local[*]</value>
</property>
<property>
<name>spark.submit.deployMode</name>
<value>client</value>
</property>
<property>
<name>spark.app.name</name>
<value>HiveOnSpark</value>
</property>
<property>
<name>spark.home</name>
<value>/opt/spark</value>
</property>
<property>
<name>hive.spark.client.maxRetries</name>
<value>5</value>
</property>
<property>
<name>spark.sql.hive.metastore.version</name>
<value>2.3.7</value>
</property>
</configuration>
spark-defaults.conf 示例:spark.driver.extraClassPath /opt/hive/lib/*
spark.executor.extraClassPath /opt/hive/lib/*
spark.sql.hive.metastore.jars /opt/hive/lib/*
spark.sql.hive.metastore.version 2.3.7
| 问题类型 | 解决方案 |
|---------|-----------|
| 版本不兼容 | 确保 Hive、Spark、Hadoop 版本匹配 |
| 配置错误 | 检查 hive-site.xml 和 spark-defaults.conf |
| 缺少 JAR 包 | 确保 Hive 的 lib 目录包含所有依赖 |
| Spark 未启动 | 检查 Spark 的日志和运行状态 |
| Hive 无法连接 Metastore | 检查 Hive Metastore 服务是否运行 |
如果你使用的是 尚硅谷提供的安装包,建议你:
如果你愿意提供具体的错误日志(如 Hive 或 Spark 的日志片段),我可以进一步帮你定位问题。
分享 创建了问题
4月20日
创建了问题
4月20日

