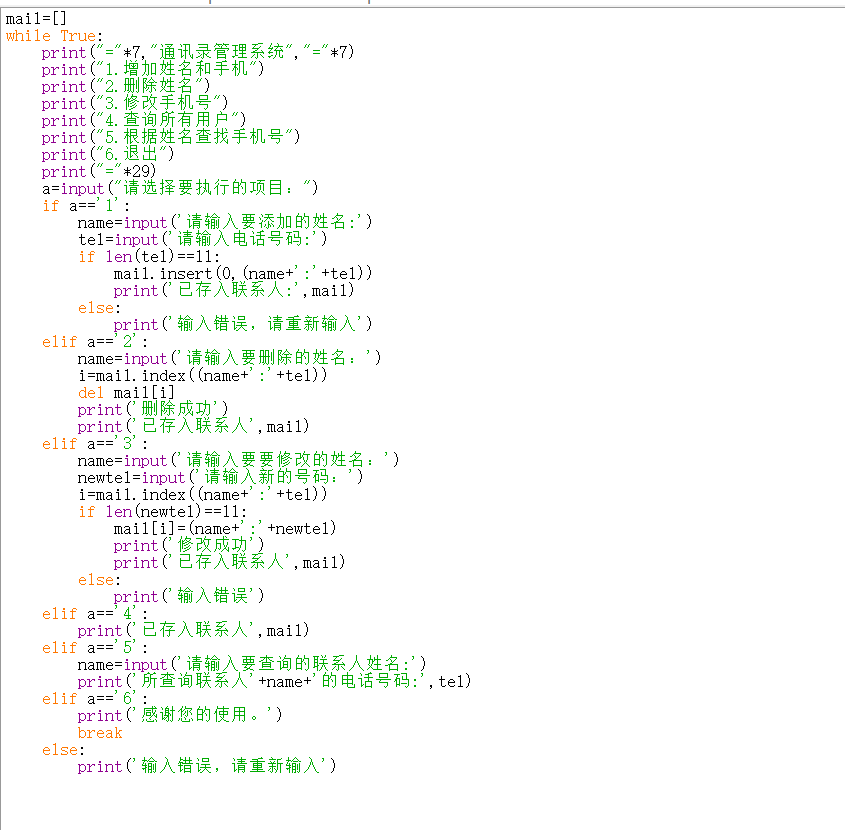
我的目的是用list做一个通讯录,输入完成后删除和修改有问题,问题我找到了,
如果修改或删除的是最后一个输入的元素,就没问题,如果修改之前的元素,就是提示元素不在列表里,问题就在name输入后,name和tel不对应,name会和最新的tel对应,所以显示元素不在列表里
想问大佬们一下,有没有可以将name和tel对应起来的办法,或者可以就只用元素中的一部分,可以索引整个元素?
急。
谢谢
————————————————
版权声明:本文为CSDN博主「-柏舟以南」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/a162202/article/details/103132512

python中列表索引的问题

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


2条回答 默认 最新
 threenewbee 2019-11-18 22:17关注
threenewbee 2019-11-18 22:17关注可以用 for 循环遍历,直到遇到相配的。 for i1 in range(0, len(mail) - 1): if mail[i1].split(':')[1] == tel: i = i1 break else: 没找到 ...解决 无用评论 打赏举报 分享
- 2023-01-02 09:43回答 1 已采纳 可以使用 try-except 语句来处理这种情况。如下代码: try: lat = result_df.loc[result_df.index == 22271]['SLat'].tolis
- 2022-07-05 11:29回答 2 已采纳 第三行的列表推导式差不多相当于下面这样写,应该可以看懂了吧: list3 = [] for slogan in list1: for name in list2: if slo
- 2022-07-01 07:53回答 4 已采纳 0 ~ len(ls)-1
- 2020-12-25 01:07python 寻找list中最大元素对应的索引方法Python 列表(List)操作方法详解python获取元素在数组中索引号的方法python通过索引遍历列表的方法numpy...列表里面序号和值的方法(三种)python 返回列表中某个值的索引方法
- 2022-06-18 15:50回答 2 已采纳 s={'小李':[77,54,57],'小张':[89,66,78]} a = [] for i in s.values(): a.append((sum(i)/len(i))//1) b
- 2023-04-22 21:24回答 2 已采纳 list1 = [9, 11, 12, 13, 14, 16, 17, 19] # 删除下标为1到4的元素(不包括下标为4的元素) del list1[1:4] # 输出删除元素后的新列表 print
- 2023-04-22 20:55回答 2 已采纳 list1=[19,12,3,4,16,8,17] list2=list1[2:5] list2.sort(reverse=True) print(list2)
- 2021-01-14 05:48大福�mkq0.39~的博客 Python与索引我一直在研究一个普通的Python代码来将数据从csv中分离出来。我的目标是使用多种策略重新创建这段代码,以便更好地理解Python。稍后将对该代码进行改进。我的代码是有效的,但有一些事情我不明白。这里...
- 2021-10-15 10:25回答 2 已采纳 # 1 ls=[] # 2 for i in range(1,6): ls.append(i) # 3 ls[1]=6 # 4 ls.index(1,7) #
- 2021-09-25 16:17回答 2 已采纳 测试程序运行正常,没有出现索引越界问题啊,输出了第一次找到了55.
- 2022-05-09 09:59回答 3 已采纳 这里你没有输出,所以什么都没有,加一个输出,就可以看到效果了 print(name)这样: 望采纳,谢谢
- 2021-02-04 00:05Joy雒金凤的博客 这个问题是由python选择通过引用传递列表的事实引起的.通常,变量按“值”传递,因此它们独立运行:>>> a = 1>>> b = a>>> a = 2>>> print b1但是,由于列表可能会相当大,而不是将...
- 2020-12-29 07:46趙瑾昀的博客 python 中如何获取列表的索引1.index方法list_a= [12,213,22,2,32]for a in list_a:print(list_a.index(a))结果: 0 1 2 3 4如果列表的没有重复的话那么用index完全可以的,那么如果列表中的元素有重复的呢?...
- 2022-12-04 14:37超级无敌有趣快乐代码搬运工的博客 Python列表索引获取
- 2021-02-09 09:24weixin_39526564的博客 如何在python列表中查找某个元素的索引方法一: 利用数组自身的特性 a.index(target), 其中a是目标list,target是需要的下标对应的值。代码如下: 可知索引为2。但是如果a中有多个76元素,这种方法仅仅能获取都第一...
- 没有解决我的问题, 去提问



悬赏问题
- ¥50 有数据,怎么建立模型求影响全要素生产率的因素
- ¥50 有数据,怎么用matlab求全要素生产率
- ¥15 TI的insta-spin例程
- ¥15 完成下列问题完成下列问题
- ¥15 C#算法问题, 不知道怎么处理这个数据的转换
- ¥15 YoloV5 第三方库的版本对照问题
- ¥15 请完成下列相关问题!
- ¥15 drone 推送镜像时候 purge: true 推送完毕后没有删除对应的镜像,手动拷贝到服务器执行结果正确在样才能让指令自动执行成功删除对应镜像,如何解决?
- ¥15 求daily translation(DT)偏差订正方法的代码
- ¥15 js调用html页面需要隐藏某个按钮