(._.) 求解呀,怎么爬取这样子的数据呀,我想让它的文件结构不变,一个一个下载要搞好久嘞
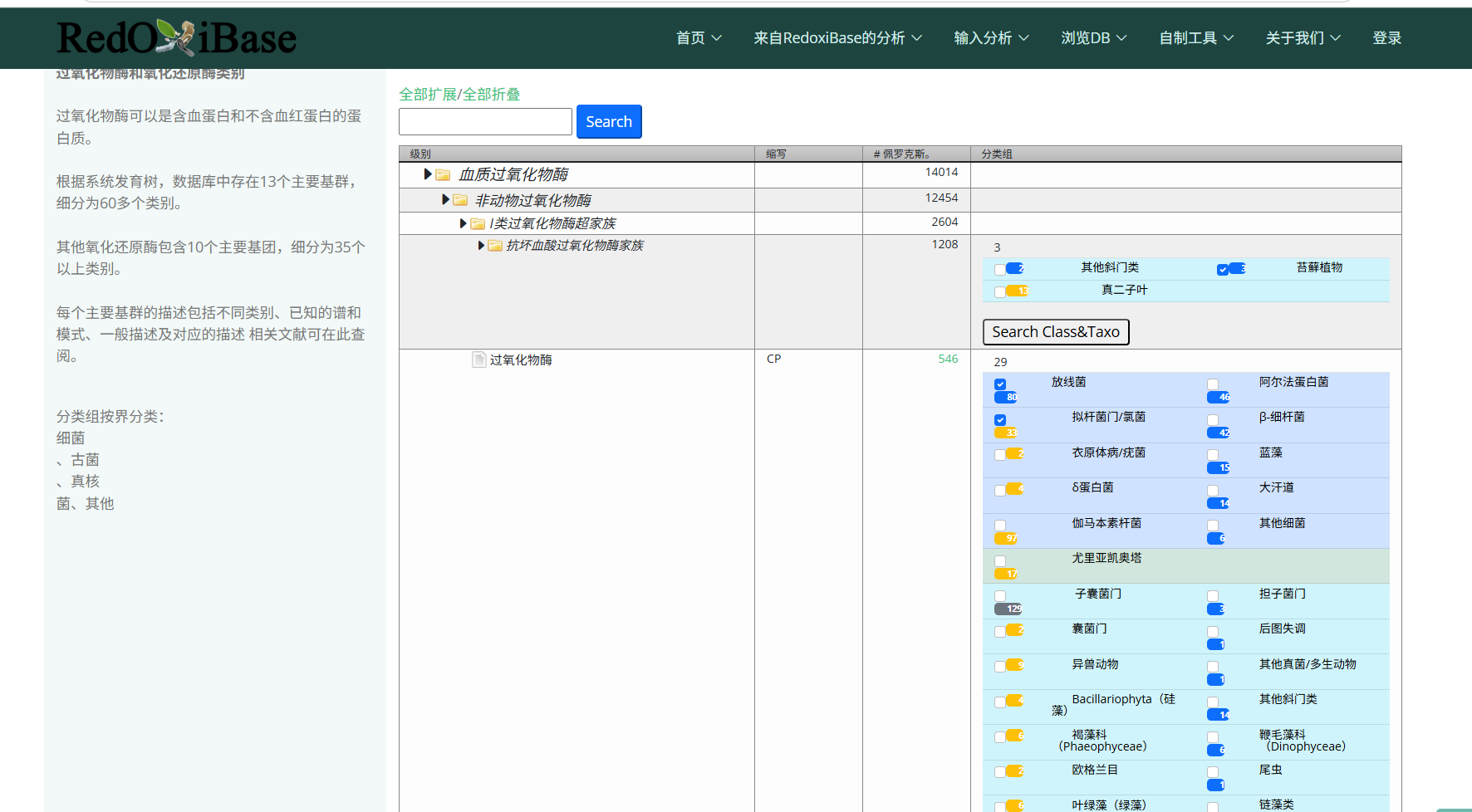

(._.) 求解呀,怎么爬取这样子的数据呀,我想让它的文件结构不变,一个一个下载要搞好久嘞
 分享
分享
晚上好🌙🌙🌙
本答案参考通义千问
你提到“爬取网站数据”,并且说“想让它的文件结构不变,一个一个下载要搞好久嘞”,这说明你希望自动下载整个网站的结构(包括目录、子页面、图片、CSS、JS等),同时保持原网站的文件结构。
下面我会详细解答如何实现这个目标,并给出具体步骤和代码示例。
你想要:
/images/、/css/、/js/ 等);wget 或 curl 命令行工具(推荐)这是最简单、最快的方式,适合大多数静态网站。
wget):wget --mirror --convert-links --adjust-extension --no-parent http://example.com
--mirror: 模拟镜像模式,递归下载。--convert-links: 转换链接为本地路径。--adjust-extension: 自动添加 .html 扩展名。--no-parent: 不爬取父目录,防止超出目标网站范围。https://www.example.com,你可以这样操作:wget --mirror --convert-links --adjust-extension --no-parent https://www.example.com
注意:请确保你有权限爬取该网站,否则可能违反服务条款或法律。
requests + BeautifulSoup + os(进阶)如果你需要更灵活的控制,比如过滤某些文件类型、处理登录、动态内容等,可以使用 Python。
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin, urlparse
# 设置目标网址
base_url = 'https://www.example.com'
# 保存路径
save_dir = './website'
# 创建保存目录
os.makedirs(save_dir, exist_ok=True)
def is_valid_url(url):
return urlparse(url).netloc == urlparse(base_url).netloc
def download_file(url, path):
try:
response = requests.get(url)
with open(path, 'wb') as f:
f.write(response.content)
print(f"Downloaded: {url}")
except Exception as e:
print(f"Error downloading {url}: {e}")
def crawl(url, depth=0):
if depth > 3: # 控制爬取深度,防止无限循环
return
try:
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 下载当前页面
filename = os.path.join(save_dir, url.replace(base_url, '').lstrip('/'))
os.makedirs(os.path.dirname(filename), exist_ok=True)
download_file(url, filename)
# 遍历所有链接
for link in soup.find_all('a'):
href = link.get('href')
if not href:
continue
full_url = urljoin(url, href)
if is_valid_url(full_url) and not full_url.endswith('.pdf'): # 可以根据需求过滤
crawl(full_url, depth + 1)
except Exception as e:
print(f"Error crawling {url}: {e}")
# 启动爬虫
crawl(base_url)
注意:此脚本会爬取所有页面和资源,但不会自动下载图片、CSS、JS 等。你可以扩展它来处理这些资源。
robots.txt 文件,不要爬取被禁止的页面。Selenium 或 Playwright 处理 JavaScript 渲染的页面。| 工具 | 用途 | 优点 |
|------|------|------|
| wget | 命令行工具 | 快速、简单、支持递归 |
| curl | 命令行工具 | 支持更多协议 |
| Python + requests + BeautifulSoup | 自定义爬虫 | 灵活、可扩展 |
| Scrapy | 框架 | 专业级爬虫框架 |
| Selenium / Playwright | 动态网页 | 支持 JS 渲染 |
重点:
- 使用
wget是最简单快速的方法;- 如果你需要定制化功能,可以使用 Python 编写爬虫;
- 一定要注意网站的爬取规则和法律法规。
如果你能提供具体的网站地址或结构,我可以帮你进一步优化代码或提供更精确的解决方案!
分享 创建了问题
5月4日
创建了问题
5月4日

