
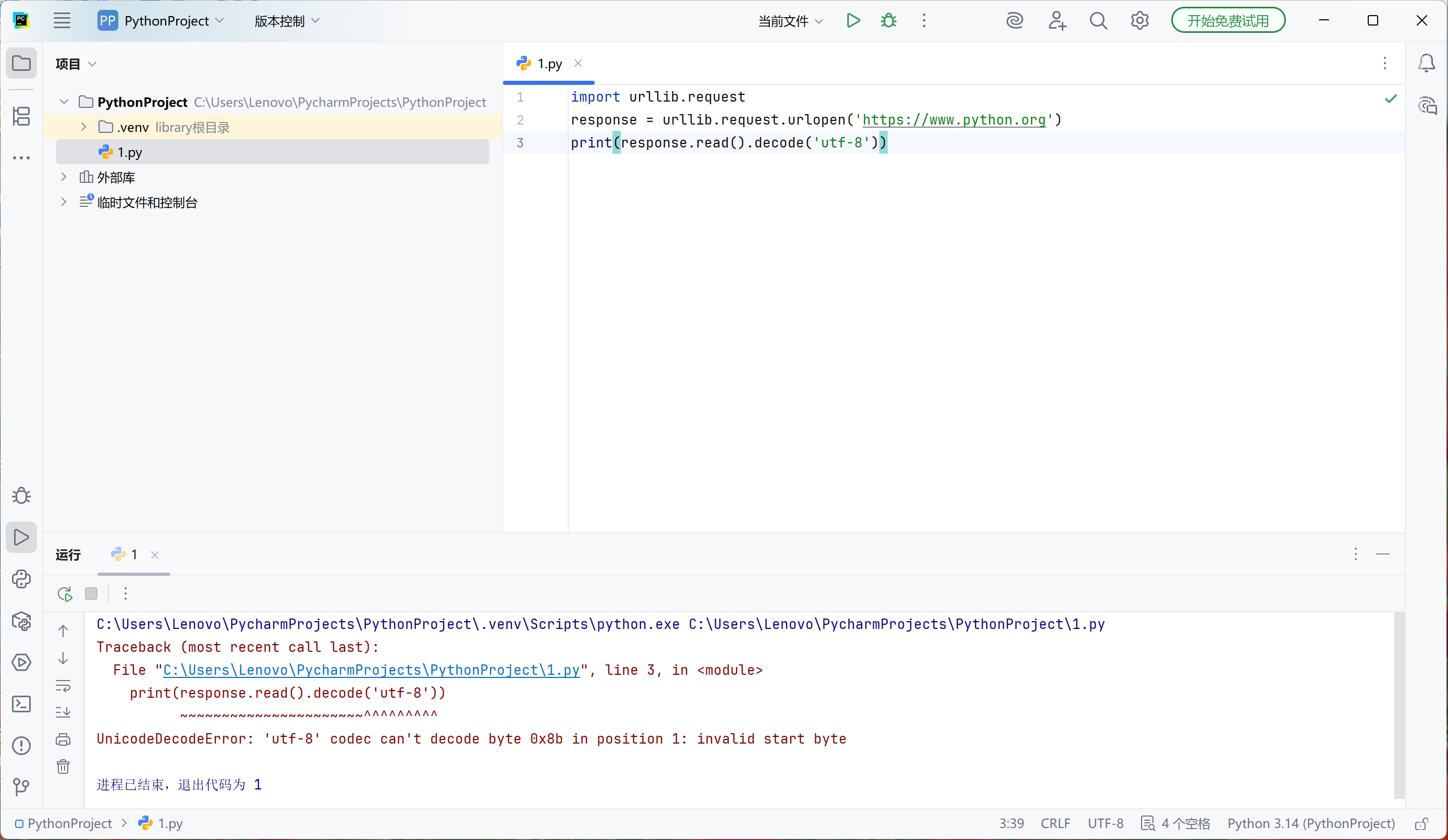
我写的代码和书上的一样,为什么不能抓取python官网呢,这是有关编程的问题


 分享
分享 将decode()方法的第二个参数改为'ignore'即可。
修改如下:
参考链接:
https://blog.csdn.net/qq_40309183/article/details/80716637
import urllib.request
response=urllib.request.urlopen('https://www.python.org')
# https://blog.csdn.net/qq_40309183/article/details/80716637
# 根据参考链接,将decode()方法的第二个参数改为'ignore'即可
# 不过爬取的网页内容乱码了
print(response.read().decode('utf-8', 'ignore'))

分享 已采纳回答
5月6日
创建了问题
5月6日
已采纳回答
5月6日
创建了问题
5月6日

