有没有佬知道这个是为什么吗?
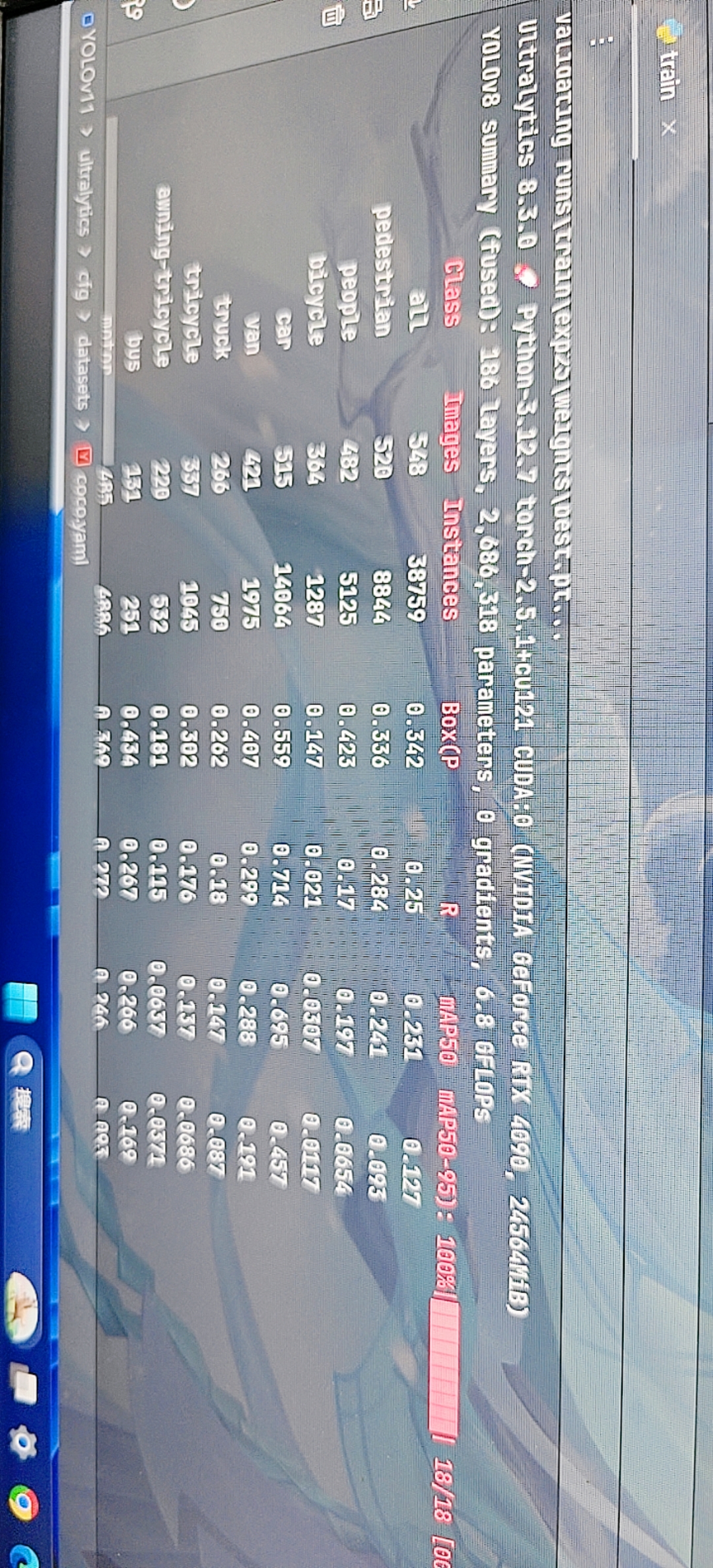
我用的yolov8训练的结果为什么精度这么低,和我看到的论文以及相关的博主的精度相比较,低了这么多啊?
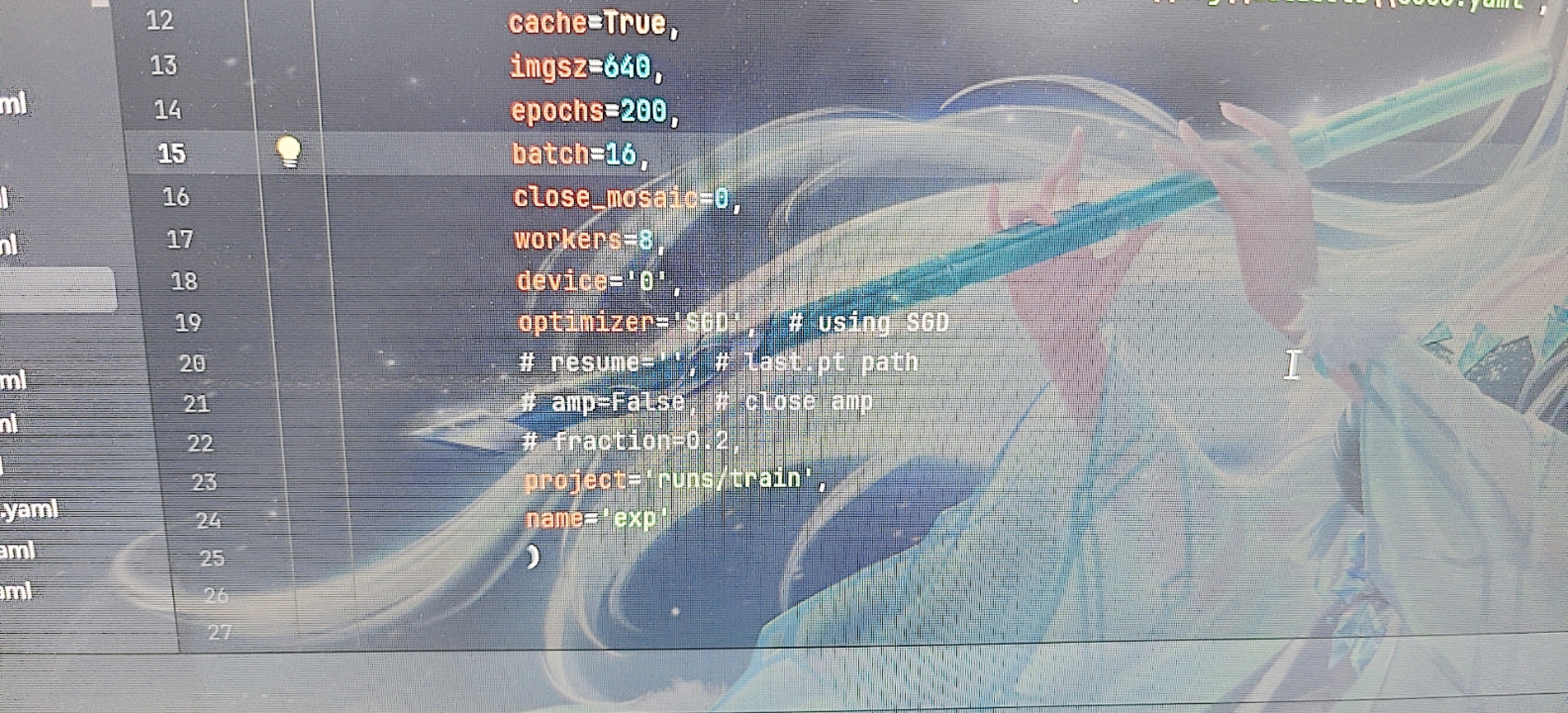
这两张图是我的环境设置和训练结果,使用的数据集链接是:
https://aistudio.baidu.com/datasetdetail/295374

有没有佬知道这个是为什么吗?
我用的yolov8训练的结果为什么精度这么低,和我看到的论文以及相关的博主的精度相比较,低了这么多啊?
这两张图是我的环境设置和训练结果,使用的数据集链接是:
https://aistudio.baidu.com/datasetdetail/295374
 分享
分享
下午好🌅🌅🌅
本答案参考通义千问
你提到在使用 YOLOv8 进行目标检测时,训练后的精度明显低于你看到的论文或博主的结果,这可能涉及到多个因素。下面我将从数据集、模型配置、训练参数、评估指标等多个方面进行分析,并提供解决方案。
import cv2
import os
def resize_images(input_dir, output_dir, size=(640, 640)):
for filename in os.listdir(input_dir):
if filename.endswith(".jpg"):
img = cv2.imread(os.path.join(input_dir, filename))
resized_img = cv2.resize(img, size)
cv2.imwrite(os.path.join(output_dir, filename), resized_img)
resize_images("data/images", "data/resized_images")
--lr 1e-4、--batch 32)。--epochs 100)。yolov8m 或 yolov8l)。python train.py --model yolov8m.pt --data your_dataset.yaml --epochs 100 --batch 32 --img 640
data.yaml 文件中配置增强策略。# data.yaml
train: ./images/train
val: ./images/val
nc: 8 # 类别数量
names: ['class1', 'class2', ...]
augment:
flipud: 0.5
fliplr: 0.5
hsv_h: 0.015
hsv_s: 0.7
hsv_v: 0.4
from sklearn.metrics import average_precision_score
import numpy as np
y_true = [1, 0, 1, 0] # 真实标签
y_scores = [0.9, 0.6, 0.7, 0.3] # 模型预测得分
mAP = average_precision_score(y_true, y_scores)
print(f"mAP: {mAP:.4f}")
nvidia-smi 查看 GPU 显存使用情况。yolov8n)。nvidia-smi
| 问题 | 解决方案 | |------|----------| | 数据集质量差 | 清洗数据、统一尺寸、检查标注 | | 参数设置不合理 | 调整学习率、批次大小、训练轮数 | | 数据增强不足 | 增加数据增强策略 | | 评估指标不一致 | 确保评估方式与论文一致 | | 显存限制 | 降低 batch size 或换用更小模型 |
如果你能提供更多细节(如训练日志、数据集描述、使用的 data.yaml 文件内容等),我可以进一步帮助你分析问题所在。
分享 创建了问题
5月8日
创建了问题
5月8日

