爬取这个网站时:http://www.mafengwo.cn/poi/18972.html,抓取不到网站源代码,网页查看时有,但是python get不到,soup、xpath都查不到,请问是什么问题,怎么爬取呢?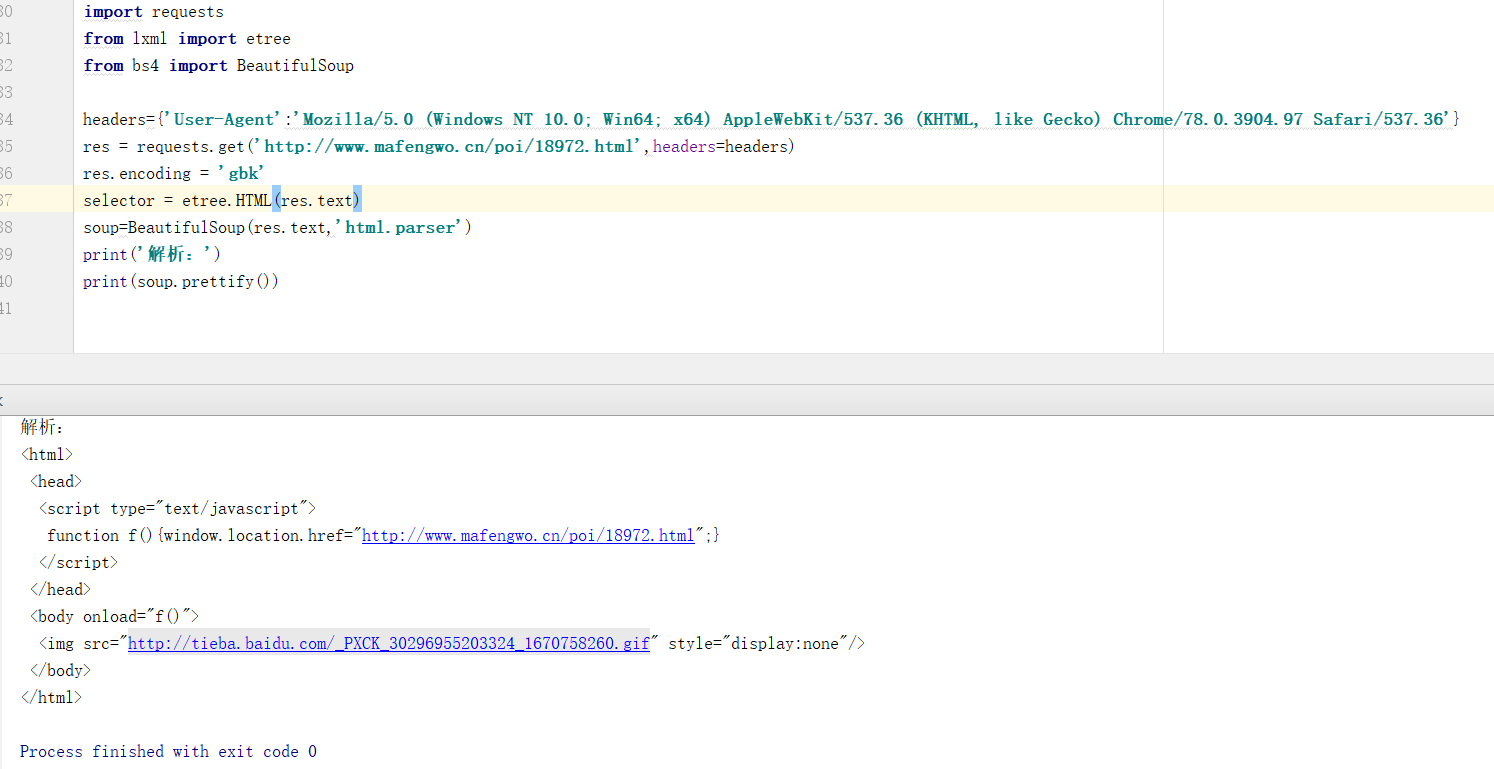

python爬取网站时抓不到网站源代码?

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


2条回答 默认 最新

- 2022-01-27 12:25回答 4 已采纳 图片是js解析出来的,xpath无效,数据在js变量里面,正则提取下数据用json.loads加载获取 代码如下 import requests import re import json def
- 2022-03-24 21:35回答 1 已采纳 我这里是可以正常运行的
- 2019-10-18 08:20回答 3 已采纳 爬虫内容解析比较方便的不是正则而是 xpath ,语法也很容易,建议试试这种: ``` from lxml import etree # 解析页面的模块 html = etree.HTML
- 2020-12-17 02:39一些动态的东西如javascript脚本执行后所产生的信息,是抓取不到的,这里暂且先给出这么一 些方案,可用于python爬取js执行后输出的信息。 1、两种基本的解决方案 1.1 用dryscrape库动态抓取页面 js脚本是通过浏览器...
- 2020-09-07 10:20回答 2 已采纳 首先 f12 抓包,看看 ajax 的 json 请求的实际地址是什么,然后用 r = requests.get(request_url) obj = r.json() print(obj.学
- 2022-08-17 17:07回答 3 已采纳 因为元素里的你要的内容是通过 ajax 请求动态加载的,可以浏览器抓包去看下,你想要的这条数据到底是哪个请求返回的,找到真正的请求,然后模拟发送就行了
- 2021-06-21 14:46回答 2 已采纳 需要添加headers。 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36
- 2020-12-25 05:51我有个需求就是抓取一些简单的书籍信息存储到mysql数据库,例如,封面图片,书名,类型,作者,简历,出版社,语种。 我比较之后,决定在亚马逊来实现我的需求。...以下源代码,命名不是很规范。。。
- 2021-08-15 19:24回答 3 已采纳 修改了一下程序,有帮助的话,望采纳! #!/usr/bin/python # -*- coding: UTF-8 -*- """ @author: Roc-xb """ import requ
- 2018-10-12 01:45回答 3 已采纳 以下是获取点击查看返回内容,测试可以完成爬取 ``` import requests def test(): s=requests.session() headers
- 2019-04-26 16:05回答 1 已采纳 现在都是动态网页,你爬取到的只是一个基本框架而已。 你可以用f12 然后检测一下http请求,基本上获取到的都是第一个请求。 后面的数据都是通过js修改后的网页。 交互式的。所以要想做复杂爬虫,
- 2020-11-23 22:27weixin_39752941的博客 然后鼠标右键点击查看源代码,发现源代码中并没有页面正中的新闻列表。这说明此网页采用的是异步的方式。也就是通过api接口获取的数据。那么确认了之后可以使用F12打开谷歌浏览器的控制台,点击Network,我们一直...
- 2022-02-24 11:15回答 2 已采纳 那个网站啊.你看下是不是写在接口中.F12开发者模式.选择XHR看下
- 2021-11-15 10:38exemplify的博客 ||由于这种网站是第一层放着只是放着单个链接(不太清楚的图片链接)然后打开获取其中单个稍微清楚的链接,这个链接也是不清楚的图片的链接,从这个网也源代码取大图的链接 ps:最好写一个time.sleep(3)来更改访问...
- 2020-02-28 11:44喔就是哦噢喔的博客 爬取步骤讲解
- 没有解决我的问题, 去提问



悬赏问题
- ¥15 Python时间序列如何拟合疏系数模型
- ¥15 求学软件的前人们指明方向🥺
- ¥50 如何增强飞上天的树莓派的热点信号强度,以使得笔记本可以在地面实现远程桌面连接
- ¥20 双层网络上信息-疾病传播
- ¥50 paddlepaddle pinn
- ¥20 idea运行测试代码报错问题
- ¥15 网络监控:网络故障告警通知
- ¥15 django项目运行报编码错误
- ¥15 STM32驱动继电器
- ¥15 Windows server update services