# -*- coding: utf-8 -*-
import sys
import io
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
# 设置默认编码为 UTF-8(解决中文输出问题)
sys.stdout = io.TextIOWrapper(sys.stdin.buffer, encoding='utf-8')
def iris_knn_grid_search():
# 1. 加载数据
data = load_iris()
X = data.data
y = data.target
# 2. 划分训练集、测试集
x_train, x_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 3. 数据标准化(KNN基于距离,必须做!)
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
# 4. 定义基础模型
knn = KNeighborsClassifier()
# 5. 定义要搜索的超参数网格(核心!)
param_grid = {
"n_neighbors": [1, 3, 5, 7, 9, 11], # 要搜索的邻居数量
"weights": ["uniform", "distance"], # 权重:均匀/距离加权
"p": [1, 2] # 距离度量:1=曼哈顿距离,2=欧氏距离
}
# 6. 网格搜索 + 5折交叉验证
# cv=5:把训练集分成5份做交叉验证
grid_search = GridSearchCV(
estimator=knn, # 要调参的模型
param_grid=param_grid, # 超参数范围
cv=5, # 5折交叉验证
n_jobs=-1 # 调用所有CPU核心加速
)
# 7. 在训练集上搜索最优参数
grid_search.fit(x_train, y_train)
# 8. 输出网格搜索最优结果
print("="*50)
print(f" 交叉验证最优准确率:{grid_search.best_score_:.4f}")
print(f" 最优超参数组合:{grid_search.best_params_}")
print(f" 最优模型:{grid_search.best_estimator_}")
print("="*50)
# 9. 用最优模型在测试集上评估
best_model = grid_search.best_estimator_
test_acc = best_model.score(x_test, y_test)
print(f" 最优模型在测试集上的准确率:{test_acc:.4f}")
if __name__ == '__main__':
iris_knn_grid_search()
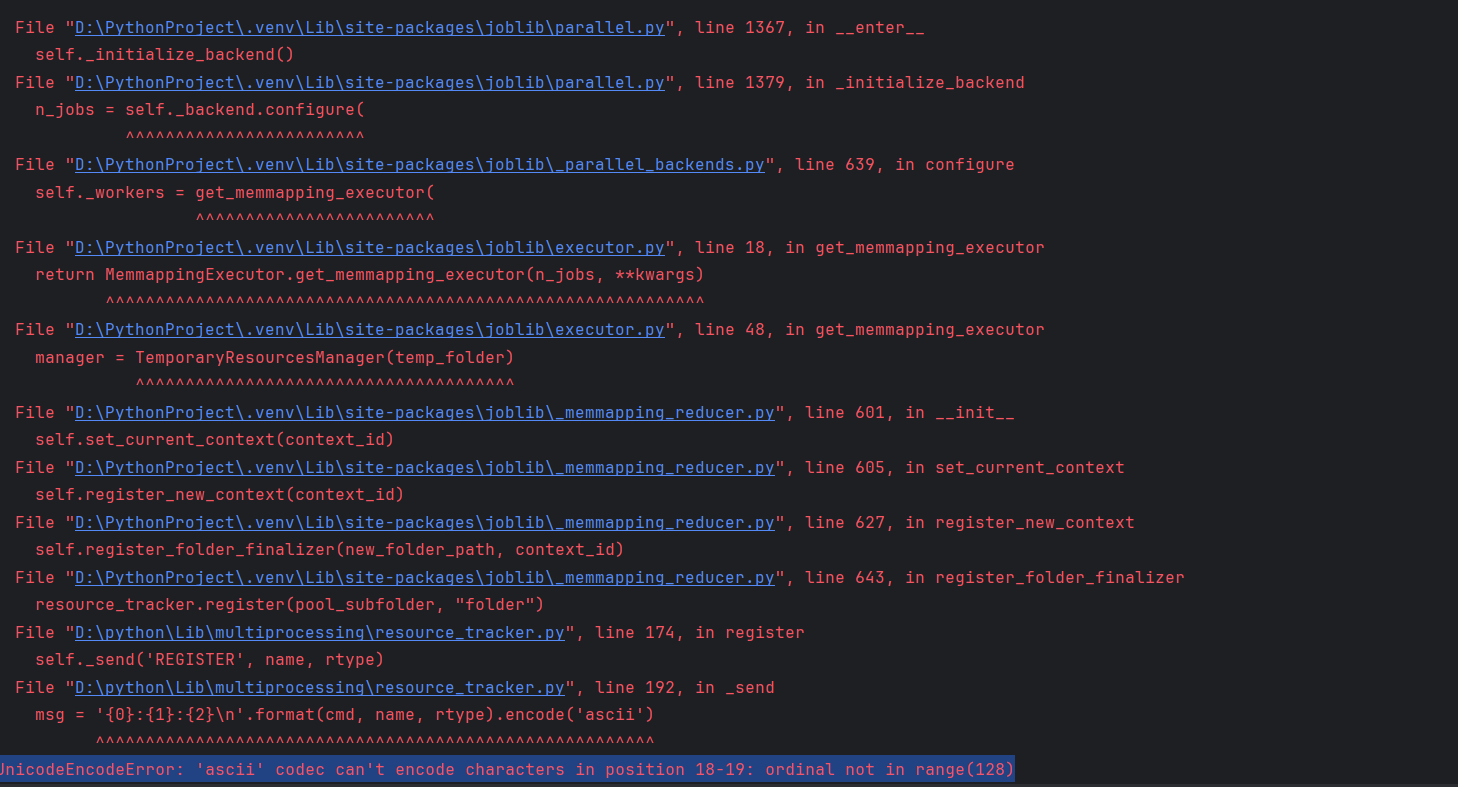
运行时报编码错误UnicodeEncodeError: 'ascii' codec can't encode characters in position 18-19: ordinal not in range(128)