
hive on spark 在运行sql时,想动态控制reduce的数据,就设置了set hive.exec.reducers.bytes.per.reducer = 256000000; 但是发觉reduce变成了1个,实际数据有大概2g左右。
后来把set hive.exec.reducers.bytes.per.reducer = 32000000; 发觉reduce变成了7个 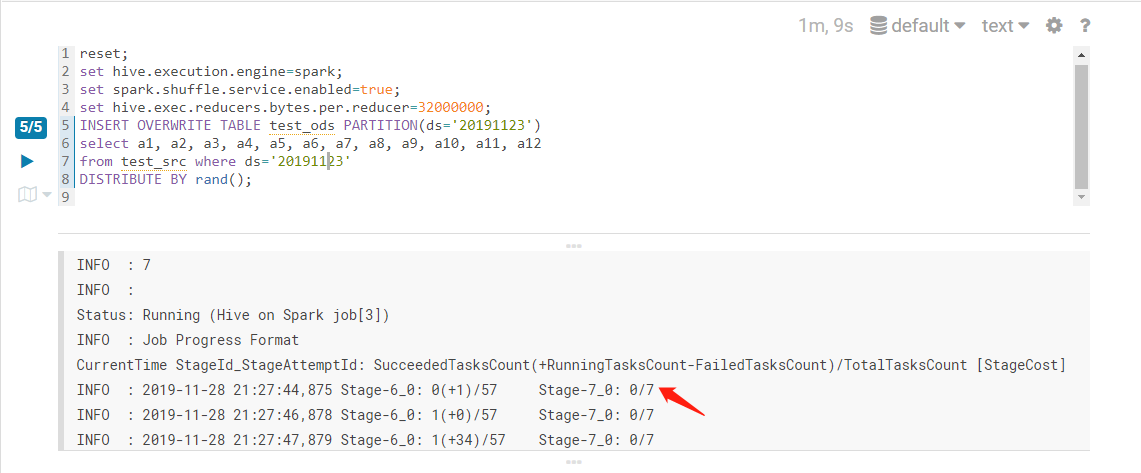
切换成 hive on mr时,set hive.exec.reducers.bytes.per.reducer = 256000000又有用了
求助~
另外发现 on mr合并小文件的参数在 on spark中设置的大小都没效果?






