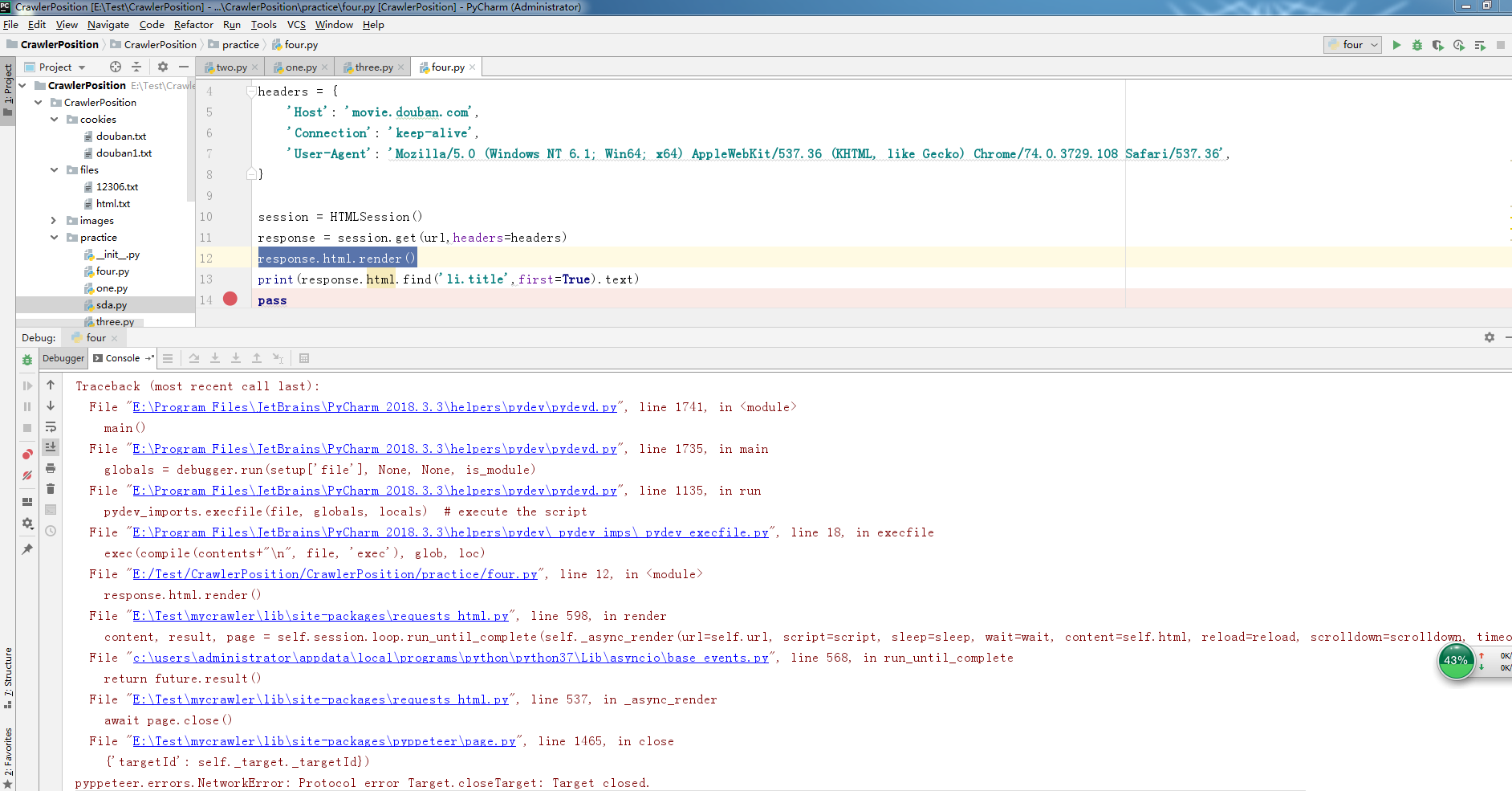
最近在使用requests-html
使用render()的时候报错,不知道为什么,哪位大神帮帮忙

requests-html render()报错

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


0条回答 默认 最新
- 2021-10-20 00:01回答 1 已采纳 建议到网站 Python Extension Packages for Windows - Christoph Gohlke
- 2021-08-06 23:34回答 2 已采纳 访问属性text时,会返回一个unicode对象,乱码问题就会常常发成在这里。参考试试: https://blog.csdn.net/xc_zhou/article/details/808933
- 2020-08-20 13:46回答 1 已采纳 看看你的代码中有没有别的叫做get的变量或者方法。 最好换一个名字。
- 2024-01-03 13:47技术流奶爸奶爸的博客 文章讨论了在Python requests_html库中使用HTMLSession的render方法时出现的超时问题。笔者在公司网页渲染工具应用中,发现自第6次调用后出现超时错误。通过排查日志和搜索,发现问题与资源释放不当有关。修复方法是...
- 2021-04-25 16:35回答 3 已采纳 我找到问题了,requests-html关联的lxml库没有升级造成的问题.刚刚重新升级安装了lxml4.6.3版本库,问题解决了.
- 2023-03-24 16:29回答 3 已采纳 response.encoding = 'utf-8' 换成如下代码看看: response.encoding = response.apparent_encoding
- 2021-10-02 18:50回答 1 已采纳 可能是你访问太快ip被封了,随机切换User-Agent或者使用代理ip再运行 python爬虫 关于requests.exceptions.ConnectionErro
- 2023-01-11 13:25丶本心灬的博客 这个错误说明没有在 openai 模块中找到 GPT 属性,也就是说你使用的 openai 库版本中没有 GPT 模型。 可能是你使用的是旧版本的openai或者在代码中没有导入相应的模块 请检查你使用的 openai 库版本是否支持 GPT ...
- 2022-02-12 11:20回答 3 已采纳 你最后的安装应该安装完了,你在代码导入试试能不能用
- 2022-05-17 00:33回答 7 已采纳 解决方法使用reuqests模拟浏览器请求的时候,需要注意的地方1、请注意添加headers2、请注意data数据是否有缺失3、如果上边都做到了,请查看获取的返回结果和报错信息是什么 根据它们的状态码
- 2022-03-26 17:07回答 1 已采纳 # _*_coding:utf-8_*_ # ! python3 """ # Using pyCharm 2021.3.2 Community and python 3.8/3.9 # Tokyo
- 2020-01-09 21:06JasonLiu1919的博客 called `story_blocks_connections.html`. (default: False) --dump-stories If enabled, save flattened stories to a file. (default: False) --fixed-model-name FIXED_MODEL_NAME If set, the name of the...
- 2022-01-11 17:25回答 2 已采纳 htmls是你上面函数download_all_htmls返回值,你需要先调用该函数 建议修改代码如下: if __name__=='__main__': htmls=download_all
- 2019-09-24 00:34denggou1889的博客 提示之后,报错!提示请求方式不被允许! methods 为什么呢?因为默认路由只允许GET访问。那么需要加一个参数methods,允许POST访问 from flask import Flask # 导入Flask类 from flask import...
- 2023-06-11 14:54zhipeng-python的博客 运行 build.py 或者 mlc_chat.rest 需要用 mlc_ai_nightly_cu121 或者 mlc_ai_nightly_vulkan的 libtvm.so 和 libtvm_runtime.so。需要注意,如果使用 mlc_chat_cli,需要用编译tvm后的 libtvm.so 和 libtvm_runtime...
- 没有解决我的问题, 去提问

