关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
and技术梦
2019-12-04 21:07
采纳率: 0%
浏览 392
首页
Java
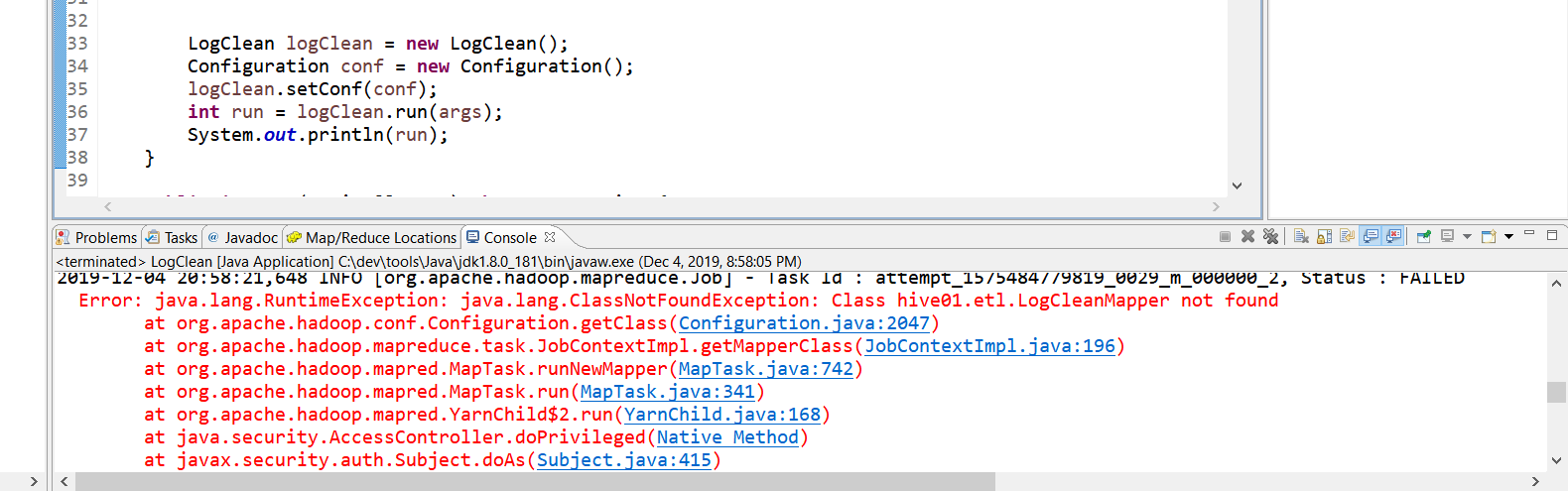
eclipse运行MapReduce程序出现找不到类
eclipse
java
如果使用setJarByClass会出现找不到类,这个应该怎么解决呢?
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
结题
收藏
举报
1
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
SeedList
2024-01-14 08:47
关注
Hadoop库没导入吧
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(0条)
向“C知道”追问
报告相同问题?
提交
关注问题
在
eclipse
运行
MapReduce
(Hadoop)
程序
的常见问题
2023-04-28 22:00
DandelionR的博客
主机名和端口在 hadoop/etc/hadoop/core-...2、M/R的端口号不要改它,依旧是50020,DFS的端口号就是在 core-site.xml 查到的端口号。只要是在代码import处
出现
报错的,都要导入相应的jar包。还要hdfs和yarn的jar包。
使用
Eclipse
编译
运行
MapReduce
程序
2019-01-06 21:26
小西转角的博客
下载
eclipse
64位: http://
eclipse
.bluemix.net/packages/mars.1/?
JAVA
-LINUX64 ...要在
Eclipse
上编译和
运行
MapReduce
程序
,需要安装 hadoop-
eclipse
-plugin文件地址https://download.csdn.net/downlo...
eclipse
编译
运行
MapReduce
程序
2020-05-07 10:56
good luck*的博客
eclipse
编译
运行
MapReduce
程序
一、环境 Ubuntu16,Hadoop2.7.1 二、安装
eclipse
你可以直接在Ubuntu的Ubuntu软件中心直接搜索安装
Eclipse
,在桌面左侧任务栏,不过我用这种方法安装之后
Eclipse
打不开,就参照了下面...
使用
Eclipse
编写
MapReduce
程序
并提交到集群
运行
2020-04-14 14:49
Captain.Y.的博客
本人是在linux虚拟机上安装的 hadoop 集群,版本3.2.1,在本地 Windows 用
Eclipse
开发 Map/Reduce
程序
,并提交到集群
运行
,我们以经典的 wordcount 为例,演示用
Eclipse
开发
MapReduce
程序
,
Eclipse
要先配置...
【Windows下】
Eclipse
尝试
Mapreduce
编程
2023-12-04 21:52
撕得失败的标签的博客
要在Windows下使用
Eclipse
进行
MapReduce
编程,你需要配置Hadoop环境,并在
Eclipse
中设置相关的开发工具。以下是一个简化的步骤指南: 安装和配置Hadoop: 下载并解压Hadoop的发行版到一个没有空格或特殊字符的目录...
Eclipse
编译、Hadoop集群
运行
MapReduce
程序
2019-03-05 13:13
红枫忆梦的博客
本文介绍的是如何在Windows中使用
Eclipse
来开发
MapReduce
程序
,并打包成jar包在已经搭建好的hadoop集群环境上
运行
。 环境 Windows 7 Hadoop 2.7.3
Eclipse
Mars Release (4.5.0) 安装Hadoop-
Eclipse
-Plugin 由于...
【图文详细】使用
Eclipse
编译
运行
MapReduce
程序
_Hadoop_2.4.1
2015-10-23 10:07
mmc2015的博客
给力星 你有多渴望,你有多付出 http://dblab.xmu.edu.cn/blog/hadoop-build-project-using-
eclipse
/ ...上篇介绍了使用命令行编译打包
运行
自己的
MapReduce
程序
,使用
Eclipse
更加方便。要在
Eclipse
上
使用
Eclipse
编译
运行
MapReduce
程序
Hadoop2.6.0_Ubuntu/CentOS
2019-09-27 11:39
Lu_kuan@的博客
虽然我们可以使用命令行编译打包
运行
自己的
MapReduce
程序
,但毕竟编写代码不方便。使用
Eclipse
,我们可以直接对HDFS 中的文件进行操作,可以直接
运行
代码,省去许多繁琐的命令。 注:本教程引用于厦门...
Eclipse
开发
mapreduce
程序
环境搭建
2019-08-30 00:19
luffy5459的博客
Eclipse
作为一个常用的
java
IDE,其使用程度虽然比不上idea那么强大,但是对于习惯使用
eclipse
开发的人来说,也不失为一个可以选择的IDE。对于喜欢
eclipse
开发的人来说,就是想让他更加的智能化,更加的友好,比如...
Ubuntu18.0.4基于Hadoop2.7.7使用
eclipse
编译
运行
MapReduce
程序
2020-05-01 10:38
rsZheng4916的博客
一、环境 Ubuntu18.0.4、Hadoop2.7.7、
Eclipse
2020.3。 二、
eclipse
安装 方式一:Ubuntu软件中心直接安装(不建议)。 方式二:手动安装(建议——必须保持联网,...这里我下载完成后存放到“下载”目录中,然后直...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告

 分享
分享


