运行环境:Anaconda+Python3.7+Spyder+Win10
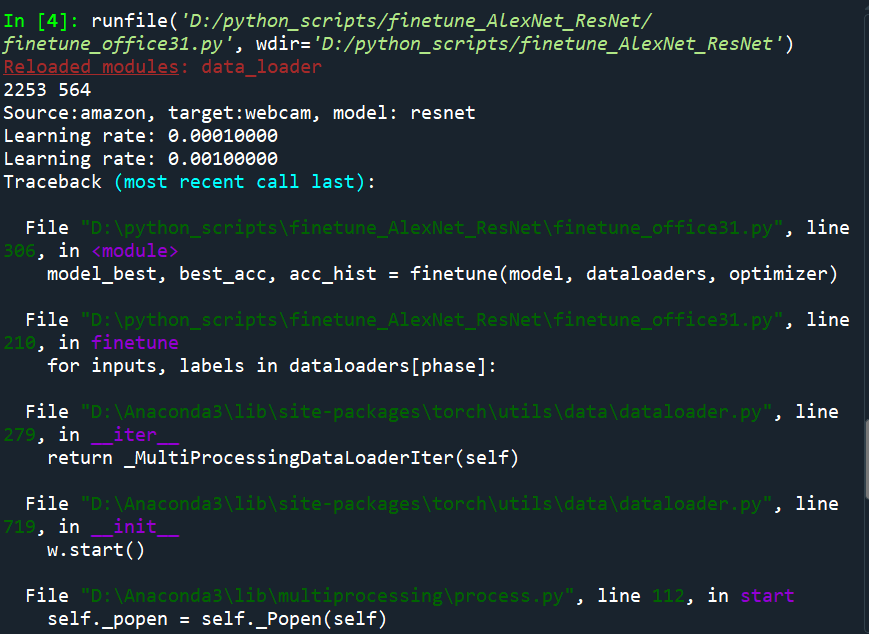
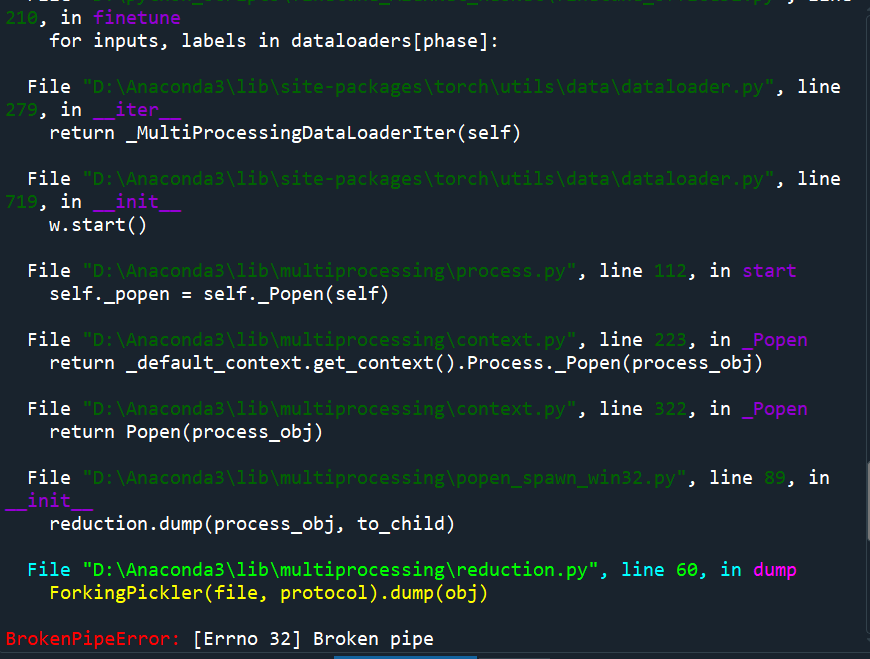
试着运行 AlexNet 网络,一直出现BrokenPipeError: [Errno 32] Broken pipe
看其他帖子,试着修改torch.utils.data.DataLoader()函数时的 num_workers 参数,但是num_workers就为0
代码源自:https://github.com/jindongwang/transferlearning/tree/master/code/deep/finetune_AlexNet_ResNet
具体如下:
from __future__ import print_function
import argparse
import data_loader
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import time
# Command setting
parser = argparse.ArgumentParser(description='Finetune')
parser.add_argument('-model', '-m', type=str,
help='model name', default='resnet')
parser.add_argument('-batchsize', '-b', type=int,
help='batch size', default=64)
parser.add_argument('-cuda', '-g', type=int, help='cuda id', default=0)
parser.add_argument('-source', '-src', type=str, default='amazon')
parser.add_argument('-target', '-tar', type=str, default='webcam')
args = parser.parse_args()
# Parameter setting
DEVICE = torch.device('cuda:' + str(args.cuda)
if torch.cuda.is_available() else 'cpu')
N_CLASS = 31
LEARNING_RATE = 1e-4
BATCH_SIZE = {'src': int(args.batchsize), 'tar': int(args.batchsize)}
N_EPOCH = 100
MOMENTUM = 0.9
DECAY = 5e-4
def load_model(name='alexnet'):
if name == 'alexnet':
model = torchvision.models.alexnet(pretrained=True)
n_features = model.classifier[6].in_features
fc = torch.nn.Linear(n_features, N_CLASS)
model.classifier[6] = fc
elif name == 'resnet':
model = torchvision.models.resnet50(pretrained=True)
n_features = model.fc.in_features
fc = torch.nn.Linear(n_features, N_CLASS)
model.fc = fc
model.fc.weight.data.normal_(0, 0.005)
model.fc.bias.data.fill_(0.1)
return model
def get_optimizer(model_name):
learning_rate = LEARNING_RATE
if model_name == 'alexnet':
param_group = [
{'params': model.features.parameters(), 'lr': learning_rate}]
for i in range(6):
param_group += [{'params': model.classifier[i].parameters(),
'lr': learning_rate}]
param_group += [{'params': model.classifier[6].parameters(),
'lr': learning_rate * 10}]
elif model_name == 'resnet':
param_group = []
for k, v in model.named_parameters():
if not k.__contains__('fc'):
param_group += [{'params': v, 'lr': learning_rate}]
else:
param_group += [{'params': v, 'lr': learning_rate * 10}]
optimizer = optim.SGD(param_group, momentum=MOMENTUM)
return optimizer
# Schedule learning rate
def lr_schedule(optimizer, epoch):
def lr_decay(LR, n_epoch, e):
return LR / (1 + 10 * e / n_epoch) ** 0.75
for i in range(len(optimizer.param_groups)):
if i < len(optimizer.param_groups) - 1:
optimizer.param_groups[i]['lr'] = lr_decay(
LEARNING_RATE, N_EPOCH, epoch)
else:
optimizer.param_groups[i]['lr'] = lr_decay(
LEARNING_RATE, N_EPOCH, epoch) * 10
def finetune(model, dataloaders, optimizer):
since = time.time()
best_acc = 0.0
acc_hist = []
criterion = nn.CrossEntropyLoss()
for epoch in range(1, N_EPOCH + 1):
# lr_schedule(optimizer, epoch)
print('Learning rate: {:.8f}'.format(optimizer.param_groups[0]['lr']))
print('Learning rate: {:.8f}'.format(optimizer.param_groups[-1]['lr']))
for phase in ['src', 'val', 'tar']:
if phase == 'src':
model.train()
else:
model.eval()
total_loss, correct = 0, 0
for inputs, labels in dataloaders[phase]:
inputs, labels = inputs.to(DEVICE), labels.to(DEVICE)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'src'):
outputs = model(inputs)
loss = criterion(outputs, labels)
preds = torch.max(outputs, 1)[1]
if phase == 'src':
loss.backward()
optimizer.step()
total_loss += loss.item() * inputs.size(0)
correct += torch.sum(preds == labels.data)
epoch_loss = total_loss / len(dataloaders[phase].dataset)
epoch_acc = correct.double() / len(dataloaders[phase].dataset)
acc_hist.append([epoch_loss, epoch_acc])
print('Epoch: [{:02d}/{:02d}]---{}, loss: {:.6f}, acc: {:.4f}'.format(epoch, N_EPOCH, phase, epoch_loss,
epoch_acc))
if phase == 'tar' and epoch_acc > best_acc:
best_acc = epoch_acc
print()
fname = 'finetune_result' + model_name + \
str(LEARNING_RATE) + str(args.source) + \
'-' + str(args.target) + '.csv'
np.savetxt(fname, np.asarray(a=acc_hist, dtype=float), delimiter=',',
fmt='%.4f')
time_pass = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_pass // 60, time_pass % 60))
return model, best_acc, acc_hist
if __name__ == '__main__':
torch.manual_seed(10)
# Load data
root_dir = 'data/OFFICE31/'
domain = {'src': str(args.source), 'tar': str(args.target)}
dataloaders = {}
dataloaders['tar'] = data_loader.load_data(
root_dir, domain['tar'], BATCH_SIZE['tar'], 'tar')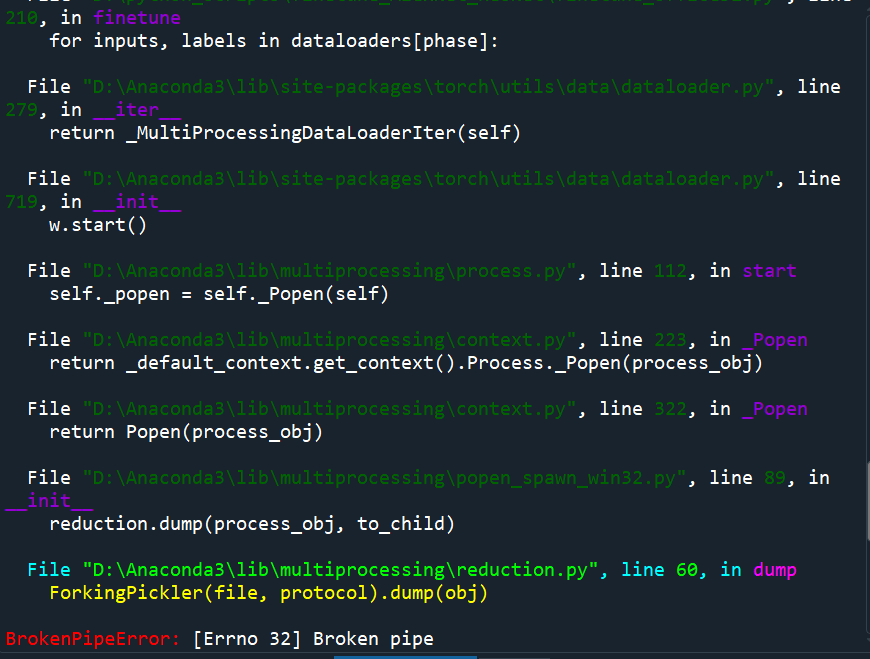
dataloaders['src'], dataloaders['val'] = data_loader.load_train(
root_dir, domain['src'], BATCH_SIZE['src'], 'src')
print(len(dataloaders['src'].dataset), len(dataloaders['val'].dataset))
# Load model
model_name = str(args.model)
model = load_model(model_name).to(DEVICE)
print('Source:{}, target:{}, model: {}'.format(
domain['src'], domain['tar'], model_name))
optimizer = get_optimizer(model_name)
model_best, best_acc, acc_hist = finetune(model, dataloaders, optimizer)
print('{}Best acc: {}'.format('*' * 10, best_acc))
报错内容如下: