最近才开始接触爬虫,盆友推荐了scrapy框架很好用,我便开始尝试。看了关于一博主关于腾讯招聘网站信息的爬取后,我心血来潮想试试爬取58同城的招聘网站的信息。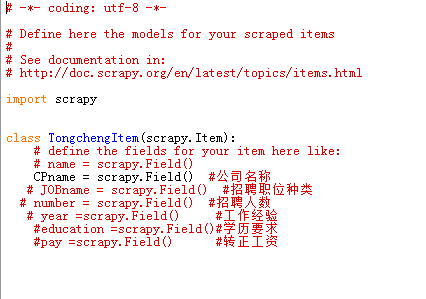图片说明](https://img-ask.csdn.net/upload/201607/04/1467596784_99350.png)
(忽略注释)结果怎么也爬取不下来,起初我以为是Xpath的问题,但我真的真的觉得我没有写错啊,求各位大神帮忙指点指点

最近才开始接触爬虫,盆友推荐了scrapy框架很好用,我便开始尝试。看了关于一博主关于腾讯招聘网站信息的爬取后,我心血来潮想试试爬取58同城的招聘网站的信息。
(忽略注释)结果怎么也爬取不下来,起初我以为是Xpath的问题,但我真的真的觉得我没有写错啊,求各位大神帮忙指点指点
 分享
分享



