
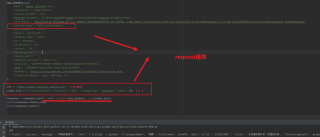
上面两幅图,第二幅为request版本,一切正常能够得到数据,第一幅为scrapy版本
目前百度已参考:(实际百度了很多)
http://www.cocoachina.com/articles/69939
https://www.cnblogs.com/qiaoer1993/p/10802735.html
集中方法在,请求头加json那个,第二就是什么body,method指定,都试过了,奇怪。
究竟有什么区别?怎么才能改正确?
request代码如下
import scrapy
import json
import requests
class BxwSpiderSpider(scrapy.Spider):
name = 'bxw_spider'
api_headers = {
'Host': 'mpapi.baixing.com',
'Connection': 'keep-alive',
'Content-Length': '24',
'BAIXING-SESSION': '$2y$10$iYbdcOD0tqZQWK1ITZc6PuIMfVDUsxItUQwepiF1VyC00ti24fPcG',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36 MicroMessenger/7.0.9.501 NetType/WIFI MiniProgramEnv/Windows WindowsWechat',
'content-type': 'application/json',
'env_version': '7.0.9',
'model': 'microsoft',
'network_type': 'wifi',
'os': 'Windows',
'os_version': '10',
'source': '70',
'source_params': '',
'source_path': '',
'template_version': 'Ver1.3.6',
'track_id': '1607997570581-6558221-0b293e26ae2048-15816961',
'udid': 'a382863f-92eb-45aa-a2b0-bca844ca6dd9',
'Referer': 'https://servicewechat.com/wxd9808e2433a403ab/42/page-frame.html',
'Accept-Encoding': 'gzip, deflate, br',
}
url = 'https://mpapi.baixing.com/v1.3.6/' # API接口
def start_requests(self):
index_json = '{"listing.getAds": {"areaId": "m28", "categoryId": "gongzuo", "page": 1}}' # 2 3
# yield scrapy.Request(
# url=self.url,
# headers=self.api_headers,
# method='POST',
# body=index_json,
# callback=self.parse,
# dont_filter=True)
yield scrapy.FormRequest(
url=self.url,
headers=self.api_headers,
formdata=eval(index_json),
callback=self.parse,
dont_filter=True)
def parse(self, response):
print('程序进入')
res_json = json.dumps(response.text)
print(res_json)
scrapy代码如下:
import scrapy
import json
import requests
class BxwSpiderSpider(scrapy.Spider):
name = 'bxw_spider'
api_headers = {
'Host': 'mpapi.baixing.com',
'Connection': 'keep-alive',
'Content-Length': '24',
'BAIXING-SESSION': '$2y$10$iYbdcOD0tqZQWK1ITZc6PuIMfVDUsxItUQwepiF1VyC00ti24fPcG',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36 MicroMessenger/7.0.9.501 NetType/WIFI MiniProgramEnv/Windows WindowsWechat',
'content-type': 'application/json',
'env_version': '7.0.9',
'model': 'microsoft',
'network_type': 'wifi',
'os': 'Windows',
'os_version': '10',
'source': '70',
'source_params': '',
'source_path': '',
'template_version': 'Ver1.3.6',
'track_id': '1607997570581-6558221-0b293e26ae2048-15816961',
'udid': 'a382863f-92eb-45aa-a2b0-bca844ca6dd9',
'Referer': 'https://servicewechat.com/wxd9808e2433a403ab/42/page-frame.html',
'Accept-Encoding': 'gzip, deflate, br',
}
url = 'https://mpapi.baixing.com/v1.3.6/' # API接口
def start_requests(self):
index_json = '{"listing.getAds": {"areaId": "m28", "categoryId": "gongzuo", "page": 1}}' # 2 3
# yield scrapy.Request(
# url=self.url,
# headers=self.api_headers,
# method='POST',
# body=index_json,
# callback=self.parse,
# dont_filter=True)
yield scrapy.FormRequest(
url=self.url,
headers=self.api_headers,
formdata=eval(index_json),
callback=self.parse,
dont_filter=True)
def parse(self, response):
print('程序进入')
res_json = json.dumps(response.text)
print(res_json)
之前爬另外一个网站,也是POST种携带请求参数,request版本就能成功,scrapy就是不行,是我使用姿势不对?
非常疑惑,百度过很多了!!!






