

大家好!我在尝试使用df.replace函数进行数据集中异常符号的替换和,但是出现了以下几个问题。
首先我创建一个简单的数据集如下:
example_data = {'A': ['1', '-', '<0.9'],
'B': ['3', '19/20','$25']
}
example_df = pd.DataFrame (example_data, columns = ['A','B'])
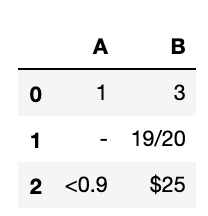
接下来使用replace函数进行特殊符号的去除。即把 - / < $ 等特殊符号去除只保留数字。
example_df = example_df.replace('/','', regex=True)
example_df = example_df.replace('$','', regex=True)#只有符号$无法去除?
example_df = example_df.replace('<','', regex=True)
example_df = example_df.replace('-','', regex=True)
example_df
问题1:使用replace函数无法去除符号“$”。请问这种情况应该怎么解决?
而且这种办法只适合知道异常符号是什么且异常符号种类很少的情况,如果想一次性替换掉所有特殊符号呢?我查询了很多方法,以下这种方法最接近,但是它一次性去掉了包含特殊符号的单元格的值。
for col in example_df.columns:
example_df[col].replace(regex=True, inplace=True, to_replace=r'[-@#&$%+/\*<>=]', value=np.nan)
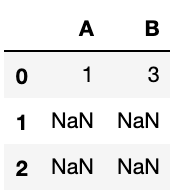
问题2: 请问如何一次性将所有特殊符号去除,并保留其所在单元格内的其他内容?
经过处理得到如下数据集:
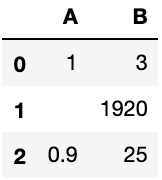
我想把缺失值使用列中位数进行填补,但是却报错“could not convert string to float: '' ”。好像是因为我把特殊符号替换成了空字符串?
for col in example_df.columns[0:]:
fill_val = example_df[col].dropna().astype(float).median()
example_df[col].fillna(fill_val,inplace=True)
问题3: 请问大家这种没有办法转换成数值型的情况下应该怎么用中位数或者平均数填补缺失值?是不是我替换特殊符号的方法还是有问题的?
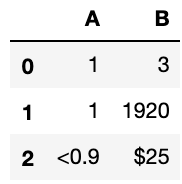
还有一个小问题~我发现如果一个单元格内只有特殊符号,那么使用None进行替换后,他们不会变成空,反而会自动填补上一行的值。请问这个是为什么呢?
#如果一个变量中只有一个特殊符号,填补成为空白之后会自动填补上一行的值?
example_df = example_df.replace('-',None, regex=True)
多谢各位大神!感激不尽!






