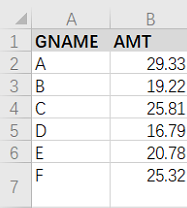
-- 3个
select t1.gname,t2.gname,t3.gname,concat(t1.gname,'+',t2.gname,'+',t3.gname,'=',t1.amt + t2.amt + t3.amt)
from test_20210402 t1
join test_20210402 t2
join test_20210402 t3
where t1.gname < t2.gname
and t2.gname < t3.gname
order by t1.gname,t2.gname,t3.gname;
-- 4个
select t1.gname,t2.gname,t3.gname,t4.gname,concat(t1.gname,'+',t2.gname,'+',t3.gname,'+',t4.gname,'=',t1.amt + t2.amt + t3.amt + t4.amt)
from test_20210402 t1
join test_20210402 t2
join test_20210402 t3
join test_20210402 t4
where t1.gname < t2.gname
and t2.gname < t3.gname
and t3.gname < t4.gname
order by t1.gname,t2.gname,t3.gname,t4.gname;
测试过程:
hive>
>
> select t1.gname,t2.gname,t3.gname,concat(t1.gname,'+',t2.gname,'+',t3.gname,'=',t1.amt + t2.amt + t3.amt)
> from test_20210402 t1
> join test_20210402 t2
> join test_20210402 t3
> where t1.gname < t2.gname
> and t2.gname < t3.gname
> order by t1.gname,t2.gname,t3.gname;
Warning: Map Join MAPJOIN[13][bigTable=t1] in task 'Stage-1:MAPRED' is a cross product
Query ID = root_20210406094633_9629ee26-61a7-4407-a105-812b168a8d83
Total jobs = 2
Launching Job 1 out of 2
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Running with YARN Application = application_1616576763401_0002
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/yarn application -kill application_1616576763401_0002
Hive on Spark Session Web UI URL: http://hp4:33610
Query Hive on Spark job[0] stages: [0]
Spark job[0] status = RUNNING
--------------------------------------------------------------------------------------
STAGES ATTEMPT STATUS TOTAL COMPLETED RUNNING PENDING FAILED
--------------------------------------------------------------------------------------
Stage-0 ........ 0 FINISHED 2 2 0 0 0
--------------------------------------------------------------------------------------
STAGES: 01/01 [==========================>>] 100% ELAPSED TIME: 6.10 s
--------------------------------------------------------------------------------------
Spark job[0] finished successfully in 6.10 second(s)
Spark Job[0] Metrics: TaskDurationTime: 5895, ExecutorCpuTime: 1005, JvmGCTime: 272, BytesRead / RecordsRead: 9028 / 12, BytesReadEC: 0, ShuffleTotalBytesRead / ShuffleRecordsRead: 0 / 0, ShuffleBytesWritten / ShuffleRecordsWritten: 0 / 0
Launching Job 2 out of 2
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Running with YARN Application = application_1616576763401_0002
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/yarn application -kill application_1616576763401_0002
Hive on Spark Session Web UI URL: http://hp4:33610
Query Hive on Spark job[1] stages: [1, 2]
Spark job[1] status = RUNNING
--------------------------------------------------------------------------------------
STAGES ATTEMPT STATUS TOTAL COMPLETED RUNNING PENDING FAILED
--------------------------------------------------------------------------------------
Stage-1 ........ 0 FINISHED 1 1 0 0 0
Stage-2 ........ 0 FINISHED 1 1 0 0 0
--------------------------------------------------------------------------------------
STAGES: 02/02 [==========================>>] 100% ELAPSED TIME: 2.02 s
--------------------------------------------------------------------------------------
Spark job[1] finished successfully in 2.02 second(s)
Spark Job[1] Metrics: TaskDurationTime: 1160, ExecutorCpuTime: 834, JvmGCTime: 32, BytesRead / RecordsRead: 8646 / 6, BytesReadEC: 0, ShuffleTotalBytesRead / ShuffleRecordsRead: 302 / 20, ShuffleBytesWritten / ShuffleRecordsWritten: 302 / 20
OK
A B C A+B+C=6
A B D A+B+D=7
A B E A+B+E=8
A B F A+B+F=9
A C D A+C+D=8
A C E A+C+E=9
A C F A+C+F=10
A D E A+D+E=10
A D F A+D+F=11
A E F A+E+F=12
B C D B+C+D=9
B C E B+C+E=10
B C F B+C+F=11
B D E B+D+E=11
B D F B+D+F=12
B E F B+E+F=13
C D E C+D+E=12
C D F C+D+F=13
C E F C+E+F=14
D E F D+E+F=15
Time taken: 29.681 seconds, Fetched: 20 row(s)
hive>
>
>
> select t1.gname,t2.gname,t3.gname,t4.gname,concat(t1.gname,'+',t2.gname,'+',t3.gname,'+',t4.gname,'=',t1.amt + t2.amt + t3.amt + t4.amt)
> from test_20210402 t1
> join test_20210402 t2
> join test_20210402 t3
> join test_20210402 t4
> where t1.gname < t2.gname
> and t2.gname < t3.gname
> and t3.gname < t4.gname
> order by t1.gname,t2.gname,t3.gname,t4.gname;
Warning: Map Join MAPJOIN[15][bigTable=t1] in task 'Stage-1:MAPRED' is a cross product
Query ID = root_20210406094947_0124d39d-d808-4510-b438-637a9d18c119
Total jobs = 2
Launching Job 1 out of 2
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
--------------------------------------------------------------------------------------
STAGES ATTEMPT STATUS TOTAL COMPLETED RUNNING PENDING FAILED
--------------------------------------------------------------------------------------
Stage-6 ........ 0 FINISHED 3 3 0 0 0
--------------------------------------------------------------------------------------
STAGES: 01/01 [==========================>>] 100% ELAPSED TIME: 1.00 s
--------------------------------------------------------------------------------------
Spark job[4] finished successfully in 1.00 second(s)
Spark Job[4] Metrics: TaskDurationTime: 501, ExecutorCpuTime: 139, JvmGCTime: 0, BytesRead / RecordsRead: 15855 / 18, BytesReadEC: 0, ShuffleTotalBytesRead / ShuffleRecordsRead: 0 / 0, ShuffleBytesWritten / ShuffleRecordsWritten: 0 / 0
Launching Job 2 out of 2
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
--------------------------------------------------------------------------------------
STAGES ATTEMPT STATUS TOTAL COMPLETED RUNNING PENDING FAILED
--------------------------------------------------------------------------------------
Stage-7 ........ 0 FINISHED 1 1 0 0 0
Stage-8 ........ 0 FINISHED 1 1 0 0 0
--------------------------------------------------------------------------------------
STAGES: 02/02 [==========================>>] 100% ELAPSED TIME: 1.00 s
--------------------------------------------------------------------------------------
Spark job[5] finished successfully in 1.01 second(s)
Spark Job[5] Metrics: TaskDurationTime: 231, ExecutorCpuTime: 92, JvmGCTime: 25, BytesRead / RecordsRead: 9623 / 6, BytesReadEC: 0, ShuffleTotalBytesRead / ShuffleRecordsRead: 265 / 15, ShuffleBytesWritten / ShuffleRecordsWritten: 265 / 15
WARNING: Spark Job[5] Spent 11% (25 ms / 231 ms) of task time in GC
OK
A B C D A+B+C+D=10
A B C E A+B+C+E=11
A B C F A+B+C+F=12
A B D E A+B+D+E=12
A B D F A+B+D+F=13
A B E F A+B+E+F=14
A C D E A+C+D+E=13
A C D F A+C+D+F=14
A C E F A+C+E+F=15
A D E F A+D+E+F=16
B C D E B+C+D+E=14
B C D F B+C+D+F=15
B C E F B+C+E+F=16
B D E F B+D+E+F=17
C D E F C+D+E+F=18
Time taken: 2.268 seconds, Fetched: 15 row(s)
hive>