

小白尝试使用requests获取网易云音乐ID的时候发现问题,网址如下。
https://music.163.com/#/discover/toplist
在网站上看出id就在a标签的href属性里,浏览器中显示的是当前音乐的id,如下图。
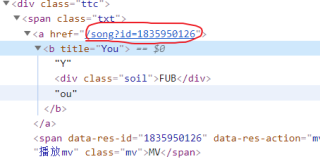
但是问题出现了,在pyc中调用requests.get获取网页html。在html中寻找需要的音乐id
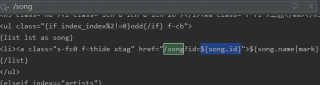
得到的html里音乐ID是${song.id}
请问是什么情况?
代码就以下四行
import requests url = "https://music.163.com/#/discover/toplist" res = requests.get(url) print(res.text)






