
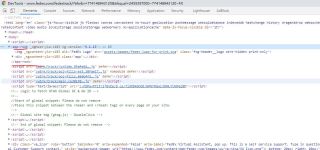
代码如下,想抓取FedEx上的物流信息。
可是用requests 请求返回的里面没有标签内容,新手很是困惑。
可是我用谷歌的开发者环境,这里明明是都代码的。
谢谢帮忙解惑。
import requests
res = requests.get('https://www.fedex.com/fedextrack/?trknbr=774148943120')
res.encoding = 'utf-8'
print(res.text)

代码如下,想抓取FedEx上的物流信息。
可是用requests 请求返回的里面没有标签内容,新手很是困惑。
可是我用谷歌的开发者环境,这里明明是都代码的。
谢谢帮忙解惑。
import requests
res = requests.get('https://www.fedex.com/fedextrack/?trknbr=774148943120')
res.encoding = 'utf-8'
print(res.text)
 分享
分享
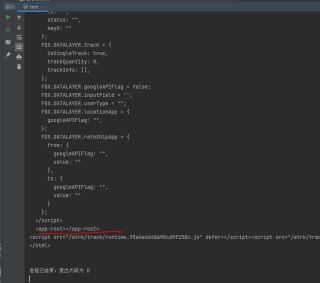
<app-root>标签里的内容是通过js读取外部json数据来动态更新的。
requests只能获取网页的静态源代码,动态更新的取不到,
对于动态更新的要用selenium 的 webdriver 爬取。
或者是通过F12控制台分析页面数据加载的链接,找到真正json数据的地址进行爬取。
你要练习requests抓取页面需要找内容直接写源代码中的页面来练习
分享



