

两个方案,一个做跨数据库的join查询,一个是把主库需要join的几个表,用主从同步的方式从主库同步到当前使用的这个库,做同库join。这两个方案哪个性能好。



2条回答 默认 最新
 CSDN专家-文盲老顾 2021-07-08 19:50关注
CSDN专家-文盲老顾 2021-07-08 19:50关注性能肯定是同库的性能好,毕竟可以有索引支持
跨库操作,一受网络影响,二受执行计划影响,索引不好调整
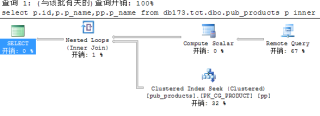
可以看到这样的执行计划
远程库中,只有1000条数据,且有索引,本地库有300万数据,同样有索引,但执行计划中,远程占了67%
本回答被题主选为最佳回答 , 对您是否有帮助呢?评论 打赏解决 1无用举报 分享
分享
- 2021-07-08 19:34回答 2 已采纳 性能肯定是同库的性能好,毕竟可以有索引支持 跨库操作,一受网络影响,二受执行计划影响,索引不好调整 可以看到这样的执行计划 远程库中,只有1000条数据,且有索引,本地库有300万数据,同样有索引,
- 2023-01-06 14:30回答 2 已采纳 1.左连接,即使条件不满足,左表的数据也会显示,如果改为inner join,不满足条件的左表数据不显示如果改为自然连接,那么不需要写on,但只能相同的列名去对应相等,如果有多个列名相同但那些列里的属
- 2015-08-13 00:52回答 1 已采纳 select a.*,b.* from a left join b on a.关联字段=b.关联字段 where a.dept_type="1"
- 2022-12-10 10:52Listen·Rain的博客 数据同步
- 2022-04-25 17:03回答 4 已采纳 执行计划截个图看一下
- 2022-04-10 21:28回答 1 已采纳 因为是按字符顺序排序的。。。 m=input().split() # 4 5 67 3 99 2 7 m=" ".join(str(i) for i in sorted(int(i) for i i
- 2021-07-16 14:22回答 1 已采纳 OutputTag获取迟到数据,二次消费
- 2022-07-11 08:00当年的春天的博客 如何构建一个安全可靠,稳定的数据存储是项目中最核心部分;在存储中JOIN一直是个老大难问题,点开文章详情轻松解决令人头疼的JOIN
- 2019-02-21 20:07回答 3 已采纳 1.sleep()方法是属于Thread类中的。而wait()方法,则是属于Object类中的。 2.sleep()方法导致了程序暂停执行指定的时间,让出cpu该其他线程,但是他的监控状态依然保持者
- 2022-01-20 17:39回答 3 已采纳 你知道分两次查询再组合时,发生了一些什么吗?应用把sql通过网络发到数据库,数据库解析sql,把整个表的数据从数据库的磁盘读出来到数据库的内存,然后通过网络把整个表传输到应用端的内存,两个表都是这样,
- 2020-11-09 16:07回答 1 已采纳 我看了下,这个差不多要逐行执行,如果表的数据比较多(例如A表有5万数据,B表有1万数据,但是B表只有100条数据是和A关联的),采用这个方法,需要对每行A表数据查一次库,没有没办只查一次(使用类似se
- 2022-09-27 17:19樵浅的博客 一、Otter 语言:java 定位:基于数据库增量日志解析,准实时同步到本机房或异地机房的mysql/oracle数据库,一个分布式数据库同步系统。 1.工作原理: 2.原理描述 1. 基于Canal开源产品,获取数据库增量日志数据 2. ...
- 2019-03-30 14:12回答 1 已采纳 感觉是不可以的,如果是。net 还行
- 2021-08-17 14:16ac.char的博客 PostgreSQL跨库数据查询及同步,postgres_fdw实战操作 数据查询及同步原理: PostgreSQL跨库操作(dblink、postgres_fdw、mysql_fdw)
- 2022-01-06 16:00ClouGence的博客 本文以 MySQL 到 ElasticSearch6 单事实表双维表为案例,介绍 CloudCanal 宽表构建和同步的操作步骤。 技术点 打宽表的必要性 关系型数据库为了应对在线业务对于并发、毫秒级响应,同时操作相对趋向 kv 化,一般基于...
- 没有解决我的问题, 去提问


问题事件
 已采纳回答
7月9日
已采纳回答
7月9日
悬赏问题
- ¥60 求一个简单的网页(标签-安全|关键词-上传)
- ¥35 lstm时间序列共享单车预测,loss值优化,参数优化算法
- ¥15 基于卷积神经网络的声纹识别
- ¥15 Python中的request,如何使用ssr节点,通过代理requests网页。本人在泰国,需要用大陆ip才能玩网页游戏,合法合规。
- ¥100 为什么这个恒流源电路不能恒流?
- ¥15 有偿求跨组件数据流路径图
- ¥15 写一个方法checkPerson,入参实体类Person,出参布尔值
- ¥15 我想咨询一下路面纹理三维点云数据处理的一些问题,上传的坐标文件里是怎么对无序点进行编号的,以及xy坐标在处理的时候是进行整体模型分片处理的吗
- ¥15 一直显示正在等待HID—ISP
- ¥15 Python turtle 画图