下面的文本提取到的是空的,要怎样写才能提取到这种标签下面没有标签包着的文本内容,

xpath提取不到 text 文本

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


4条回答 默认 最新
 CSDN专家-HGJ 2021-07-19 17:35关注
CSDN专家-HGJ 2021-07-19 17:35关注选取其所在标签,然后用text属性获取其下所有文本值。
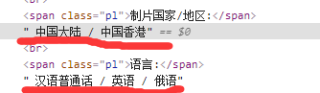
txt='''<div class='item'> <span class="p1">制片国家/地区:</span> "中国大陆 / 中国香港" <br> <span class="p1">语言:</span> "普通话 / 英语" </div>''' from bs4 import BeautifulSoup soup=BeautifulSoup(txt,'html.parser') res=soup.select_one('div.item').text#取多项的话,用select,遍历取其元素的text属性值即可 print(res)制片国家/地区: "中国大陆 / 中国香港" 语言: "普通话 / 英语"如果对你有帮助,请点击采纳按钮支持一下。
本回答被题主选为最佳回答 , 对您是否有帮助呢?评论 打赏解决 1无用举报 分享
- 2021-07-19 17:03回答 4 已采纳 选取其所在标签,然后用text属性获取其下所有文本值。 txt='''<div class='item'> <span class="p1">制片国家/地区:</span
- 2022-05-30 23:15回答 2 已采纳 不知道是不是有个逗号的原因,然后把后面给截断了,可以试试正则去提取 import requests,re url = 'https://www.renren.com/login' rep=reque
- 2021-09-30 17:40回答 2 已采纳 你检查下这个网页中的内容是不是通过js代码读取外部json数据来动态更新的。requests只能获取网页的静态源代码,动态更新的内容取不到。对于动态更新的内容要用selenium 来爬取。 或者是通
- 2021-09-14 21:06shun201207的博客 python xpath提取text的两个坑 当P下面有无文本的text 标签时,获取到的选择器里也包含这个文件,因此,此时用contact_first()时得到的是第一个 1.下面这个是p标签下无其它标签,用extract_first()可以获取到 ![在...
- 2022-01-27 12:25回答 4 已采纳 图片是js解析出来的,xpath无效,数据在js变量里面,正则提取下数据用json.loads加载获取 代码如下 import requests import re import json def
- 2019-03-27 09:11回答 2 已采纳 要爬取的是中国货币网上的内容,发现不是静态网页,最后找到了request返回包含json数据的url,得到了所需的信息~ ``` r = requests.get(url) pr
- 2021-11-22 20:58回答 2 已采纳 表达式有问题,这个html源码你用xpath取得话是有两个值的,所以索引0是搜不到。 正确写法应该是把0换成2
- 2022-10-02 21:36EXI-小洲的博客 Python Xpath解析 数据提取 基本使用
- 2022-12-12 01:38回答 2 已采纳 数据有可能是动态加载的,你没有爬到,先打印整个页面内容,搜索一下看有没有你需要的内容,没有的话,那内容就是动态加载的,request肯定爬取不到,那xpath肯定就提取不了呗!1.对于动态加载的数据,
- 2022-11-04 09:12回答 1 已采纳 xpath 定位不是这个吧?我用xpath是 //*[@id="su"]
- 2021-12-18 14:35回答 1 已采纳 discribe =html.xpath('normalize-space(//div[@class="container-fluid"]//div[@class="work_b"]//text()
- 2020-12-07 21:18代码小风的博客 Python操作Xpath lxml库 lxml是一个HTML/XML的解析器,主要的功能是如何解析和提取HTML/XML数据 我们可以利用xpath语法来快速的定位特定元素以及节点信息 安装lxml pip install lxml from lxml import etree from ...
- 2023-03-17 10:32回答 4 已采纳 https://blog.csdn.net/superwfei/art
- 2020-12-06 14:53weixin_39923157的博客 Python 2.7Pycharm 5.0.3问题再写一个markdown自动引用的小脚本的时候新出现的问题,也就是利用xpath取出字符串的问题,记录一下取出如下字符串这里写图片描述我要取出mrlevo520的内容,怎么取呢,很多方法,bs4也...
- 2023-02-04 18:59甲寅Emore的博客 本文概述了Python3利用Xpath获得网页信息并返回的方法,内容有 Xpath的梗概和安装 Xpath常用规则 使用Xpath 接入HTML文本 从内存中读取 从文件中读取 查找节点 所有节点 指定节点 属性多值匹配 多属性匹配 选择顺序 ...
- 没有解决我的问题, 去提问


问题事件
 已采纳回答
7月20日
已采纳回答
7月20日-
创建了问题
7月19日
悬赏问题
- ¥50 三种调度算法报错 采用的你的方案
- ¥15 关于#python#的问题,请各位专家解答!
- ¥200 询问:python实现大地主题正反算的程序设计,有偿
- ¥15 smptlib使用465端口发送邮件失败
- ¥200 总是报错,能帮助用python实现程序实现高斯正反算吗?有偿
- ¥15 对于squad数据集的基于bert模型的微调
- ¥15 为什么我运行这个网络会出现以下报错?CRNN神经网络
- ¥20 steam下载游戏占用内存
- ¥15 CST保存项目时失败
- ¥20 java在应用程序里获取不到扬声器设备