- 程序的运行结果为:
arr = np.array([[1, 2, 3, 4, 5],[4, 5, 6, 7, 8], [7, 8, 9, 10, 11]])
print('一:索引结果为:',arr[1,2:5])
print('二:索引结果为:',arr[0:,2:])
print('三;索引结果为:',arr[:,4])
表1:meal_detail.csv - 程序的运行结果为:
detail= pd.read_csv('meal_detail1.csv',encoding='gbk')print('一: ', detail.size)
print('二:', detail.columns)
print('三;', detail.shape) - 程序的运行结果为:
detail= pd.read_csv('meal_detail1.csv',encoding='gbk')
dishes_name = detail.iloc[:,3]orderDish = detail.loc[:,['order_id','dishes_name']]
print('使用iloc提取列为:', dishes_name)
print('使用loc提取order_id和dishes_name列的size为:', orderDish) - 程序的运行结果为:
detail= pd.read_csv('meal_detail1.csv',encoding='gbk')detailGroup= detail[['order_id','counts','amounts']].groupby(by = 'order_id')
print('订单详情表分组后每组的均值为:\n', detailGroup.mean().head())print('订单详情表分组后每组的大小为:','\n', detailGroup.size().head())(备注:detailGroup.mean()保留小数点后2位)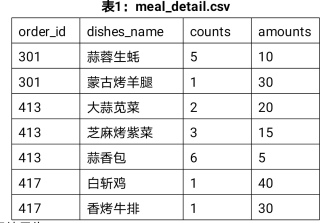

Python解题思路代码

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


1条回答 默认 最新

 关注
关注一:索引结果为: [6 7 8] 二:索引结果为: [[ 3 4 5] [ 6 7 8] [ 9 10 11]] 三;索引结果为: [ 5 8 11] 一: 28 二: Index(['order_id', 'dishes_name', 'counts', 'amounts'], dtype='object') 三; (7, 4) 使用iloc提取列为: 0 10 1 30 2 20 3 20 4 5 5 40 6 30 Name: amounts, dtype: int64 使用loc提取order_id和dishes_name列的size为: order_id dishes_name 0 301 蒜蓉生蚝 1 301 蒙古烤鸡腿 2 413 大蒜苋菜 3 413 芝麻烤紫菜 4 413 蒜香包 5 417 白斩鸡 6 417 香烤牛排 订单详情表分组后每组的均值为: counts amounts order_id 301 3.000000 20.0 413 3.333333 15.0 417 1.000000 35.0 订单详情表分组后每组的大小为: order_id 301 2 413 3 417 2 dtype: int64本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2022-05-25 10:22回答 1 已采纳 用个for循环,打印1,2,3一直到最大数,然后从最大数往小输出 num = int(input()) for i in range(1,num+1): print(i,end='') fo
- 2022-11-14 22:52回答 2 已采纳 小写转大写可以用字符串的upper()函数,全是车牌号,可以用提取车牌字符串里的第一个字符,来判断是否是浙江省的车牌,然后用第二个字符来判断车牌归属地属于浙江省的哪个市,代码如下:参考链接:https
- 2021-12-29 13:11回答 1 已采纳 t=int(input()) for i in range(t): inp = list(map(int,input().split())) n,lst = inp[0],inp[1
- 2024-01-16 15:33解题思路:找到规律即可 注意事项:主要要注意分段后可能剩下的不能组成k位的数值取值情况
- 2021-07-01 20:06回答 1 已采纳 逐行读取文件,用eval()计算即可 with open(r'data.txt', 'r', encoding='utf-8') as fileObj: for line in fileObj
- 2022-11-17 09:31回答 7 已采纳 等我三小时速成Python,再写给你 import math # 题目一 def circle(): f=float(input('请输入圆的半径R:')) print('周长L:
- 2021-10-22 17:20回答 1 已采纳 你仔细看逻辑关系第二种算法里面循环5次,total是不断在循环,不断增加的而第一种,循环一次,直接return了说白了,第二种要求5个人都分到鱼,而第一种只要求第一个人分到鱼,后面的人不管了,那能一样
- 2022-06-03 06:30敲代码的哆来a梦的博客 思路实现:采用递归的方式去实现全排列组合
- 2021-05-14 15:29回答 3 已采纳 如果对你有帮助,可以点击我这个的回答右上方的【采纳】按钮,给我个采纳吗,谢谢。
- 2021-12-19 19:03回答 1 已采纳 你题目的解答代码如下: n = int(input("请输入一个整数:")) s = "" t = '0123456789ABCDEF' while True: s = t[n%16]+s
- 2022-04-14 16:41回答 1 已采纳 那不是说在[0,6]之间。这个文章的作者可能表达是 0是星期天,6是星期6
- 2022-04-10 12:22Marlowee的博客 第十三届蓝桥杯省赛B组Python解题思路详解
- 2021-06-26 18:00回答 2 已采纳 n = int(input('type a number:')) x = [z+1 for z in range(1,2*n+1)] while len(x)>0: print(','
- 2021-01-13 00:54Python解题代码和实验报告(包含详细解题思路)
- 2023-02-03 17:33业里村牛欢喜的博客 下列分享一些解题的思路。附属在代码里面,进行讲解。
- 没有解决我的问题, 去提问



问题事件
 系统已结题
9月14日
系统已结题
9月14日 已采纳回答
9月6日
已采纳回答
9月6日-
创建了问题
9月6日
悬赏问题
- ¥15 腾讯云如何建立同一个项目中物模型之间的联系
- ¥30 VMware 云桌面水印如何添加
- ¥15 用ns3仿真出5G核心网网元
- ¥15 matlab答疑 关于海上风电的爬坡事件检测
- ¥88 python部署量化回测异常问题
- ¥30 酬劳2w元求合作写文章
- ¥15 在现有系统基础上增加功能
- ¥15 远程桌面文档内容复制粘贴,格式会变化
- ¥15 这种微信登录授权 谁可以做啊
- ¥15 请问我该如何添加自己的数据去运行蚁群算法代码