

具体过程就是,在写爬取一个小说网站的小爬虫
大概架构是:
1、先从目录页入手找到各个子页面的地址
2、再通过子页面地址用正则抓取到正文内容
3、将上述第二部,抓取正文内容的过程,改为异步协程的方法,同时抓取
现在1、2步以实现,在同步状态下可以正常运行;但是根据小子网上学的改为异步协程方法进行修改后;却报错无法执行,望老鸟指教
以下是拿来练手的小说地址:
这个三国很核理(于秋陨S)最新章节免费在线阅读_这个三国很核理小说全文在线阅读-起点中文网
这个三国很核理是于秋陨S创作的历史类小说,起点中文网提供这个三国很核理免费在线阅读,此外还提供这个三国很核理最新章节在线阅读。起点中文网为您创造这个三国很核理无广告、无弹窗在线阅读。
https://book.qidian.com/info/1030136856/#Catalog
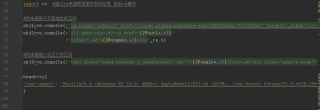
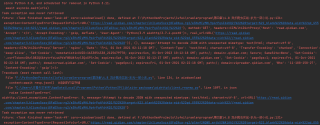
报错截图
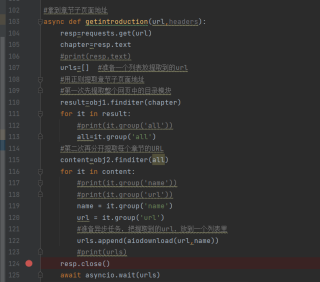
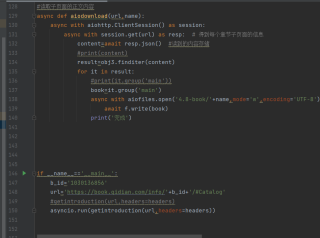
源代码:
import re
import requests
import asyncio
import aiohttp
import aiofiles
import json
#用来提取子页面地址的正则
obj1=re.compile(r'<a class="subscri" href="//read.qidian.com/hankread/1030136856/94755936/" target="_blank"><!--<em class="btn"><b class="iconfont"></b>分卷阅读</em>--></a>.*?<ul class="cf">(?P<all>.*?) <div class="book-content-wrap cf">',re.S)
obj2=re.compile(r'<li data-rid=.*?><a href="(?P<url>.*?)'
r'title=".*?">(?P<name>.*?)</a>',re.S)
#用来提取小说正文的正则
obj3=re.compile(r'<div class="read-content j_readContent" id="">(?P<main>.*?)</div>.*?<div class="admire-wrap">',re.S)
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36 OPR/78.0.4093.184'
}
#提取到的页面子链接需要补充:https:
child_supplement='https:'
#拿到章节子页面地址
async def getintroduction(url,headers):
resp=requests.get(url)
chapter=resp.text
#print(resp.text)
urls=[] #准备一个列表放提取到的url
#用正则提取章节子页面地址
#第一次先提取整个网页中的目录模块
result=obj1.finditer(chapter)
for it in result:
#print(it.group('all'))
table=it.group('all')
#第二次再分开提取每个章节的URL
content=obj2.finditer(table)
for it in content:
#print(it.group('name'))
#print(it.group('url'))
name = it.group('name')
url =child_supplement+it.group('url') #对提取到的链接进行拼接
#准备异步任务,把提取到的url,放到一个列表里
urls.append(aiodownload(url,name))
#print(urls)
resp.close()
await asyncio.wait(urls)
#读取子页面的正文内容
async def aiodownload(url,name):
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp: # 得到每个章节子页面的信息
content=await resp.json() #读到的内容存储
#print(content)
result=obj3.finditer(content)
for it in result:
#print(it.group('main'))
book=it.group('main')
async with aiofiles.open('4.8-book/'+name,mode='w',encoding='UTF-8') as f:
await f.write(book)
print('完成')
if __name__=='__main__':
b_id='1030136856'
url='https://book.qidian.com/info/'+b_id+'/#Catalog'
#getintroduction(url,headers=headers)
asyncio.run(getintroduction(url,headers=headers))









