以下是代码:
import json
import requests
import re
import datetime
import csv
import time
f=open('C:\\Users\\liu\\Desktop\\python\\年报爬取\\连续天数'+'stkcd.csv',mode='w',encoding='gbk',newline='')
writer=csv.writer(f)
head=['stkcd']
writer.writerow(head)
begin=datetime.date(2021,4,1)
end=datetime.date(2021,4,30)
for i in range((end-begin).days+1):
time.sleep(1)
searchDate=str(begin + datetime.timedelta(days=i))
responsel=requests.get(
'http://query.sse.com.cn/commonQuery.do?jsonCallBack=jsonpCallback87383849&isPagination=true&pageHelp.pageSize=25&pageHelp.cacheSize=1&type=inParams&sqlId=COMMON_PL_SSGSXX_ZXGG_L&START_DATE=2021-04-01&END_DATE=2021-04-30&SECURITY_CODE=&TITLE=%E5%B9%B4%E6%8A%A5&BULLETIN_TYPE=0101&pageHelp.pageNo=1&pageHelp.beginPage=1&pageHelp.endPage=1&_=1635924801654'
,
headers={'Referer':'http://www.sse.com.cn/disclosure/listedinfo/announcement/'}
)
json_str1 = responsel.text[19:-1]
data1=json.loads(json_str1)
max_page=data1['pageHelp']['pageCount']+1
for j in range(1,max_page):
response=requests.get(
'http://query.sse.com.cn/commonQuery.do?jsonCallBack=jsonpCallback87383849&isPagination=true&pageHelp.pageSize=25&pageHelp.cacheSize=1&type=inParams&sqlId=COMMON_PL_SSGSXX_ZXGG_L&START_DATE=2021-04-01&END_DATE=2021-04-30&SECURITY_CODE=&TITLE=%E5%B9%B4%E6%8A%A5&BULLETIN_TYPE=0101&pageHelp.pageNo=1&pageHelp.beginPage=1&pageHelp.endPage=1&_=1635924801654'
,
headers={'Referer':'http://www.sse.com.cn/disclosure/listedinfo/announcement/'}
)
json_str=response.text[19:-1]
data=json.loads(json_str,strict=False)
for report in data['result']:
download_url='http://www.sse.com.cn/'+report['URL']
if re.search('年度报告',report['TITLE'],re.S):
if re.search('摘要',report['TITLE'],re.S):
pass
else:
filename=report['SECURITY_CODE']+report['TITLE']+searchDate+'.pdf'
print(filename)
writer.writerow([report['SECURITY_CODE']])
if re.search('ST',report['TITLE'],re.S):
filename=report['SECURITY_CODE']+'-ST'+searchDate+'.pdf'
download_url='http://www.sse.com.cn/'+report['URL']
resource=requests.get(download_url,stream=True)
with open('C:\\Users\\liu\\Desktop\\python\\年报爬取\\连续天数'+filename,'wb') as fd:
for y in resource.iter_content(102400):
fd.write(y)
print(filename,'完成下载')
else:
download_url='http://www.sse.com.cn/'+report['URL']
resource=requests.get(download_url,stream=True)
with open('C:\\Users\\liu\\Desktop\\python\\年报爬取\\连续天数'+filename,'wb') as fd:
for y in resource.iter_content(102400):
fd.write(y)
print(filename,'完成下载')
f.close()
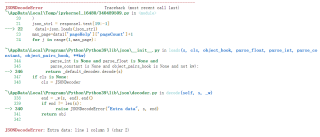
以下是运行后报错的内容: