为什么不能自动翻页爬取呀,没看出哪里有毛病呀,希望能说一下原理呀,谢谢啦啦
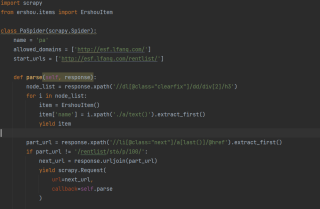
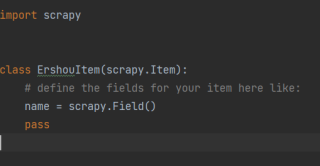
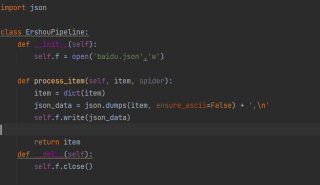
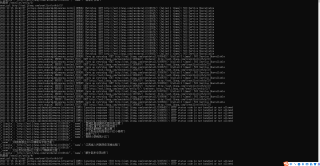
还有下面这个,点开新的页面爬取数据,为什么爬取不到呢?哪里有错误谢谢
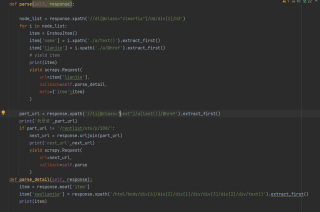
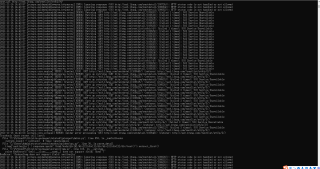
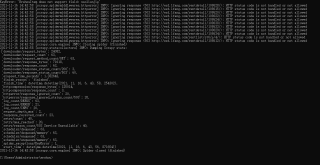
运行代码
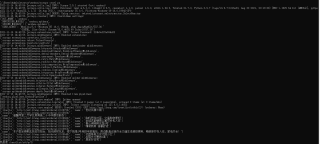

为什么不能自动翻页爬取呀,没看出哪里有毛病呀,希望能说一下原理呀,谢谢啦啦
还有下面这个,点开新的页面爬取数据,为什么爬取不到呢?哪里有错误谢谢
运行代码
 分享
分享
scrapy框架里面 start_urls里面装的是网页列表,你在上面贴的代码里只放了一个url,所以他只会一直爬这一个网页。
用for循环构造出url,然后添加进statrt_urls,然后再运行就解决了。
分享 系统已结题
11月24日
系统已结题
11月24日 已采纳回答
11月16日
修改了问题
11月16日
赞助了问题酬金
11月14日
已采纳回答
11月16日
修改了问题
11月16日
赞助了问题酬金
11月14日




