
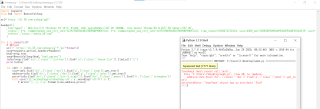
前面infos的find_all没有报错,print(infos)可以成功,但到下面爬具体内容的时候就显示AttributeError: 'NoneType' object has no attribute 'find_all',请问该怎么解决呀

 分享
分享
观察了一下此网站,是他的地理位置那一栏的标签顺序有变化,所以find未找到对应的值,导致解析失败无数据,建议换一种解析库,代码如下:
import time
import requests
from lxml import etree
headers={'User-Agent':'',
'Referer':'https://dl.58.com/zufang/pg2/'} # headers参数自己补充一下,通过测试,只需要Referer和请求头即可
for u in range(1,4):
url='https://dl.58.com/zufang/pg2/pn'+str(u)+'/'
print(url)
res=requests.get(url,headers=headers,proxies=test_IP.proxies)
dom=etree.HTML(res.text)
title=dom.xpath("//div[@class='list-box']/ul[@class='house-list']/li/div[@class='des']/h2/a/text()")
area=dom.xpath("//div[@class='list-box']/ul[@class='house-list']/li/div[@class='des']/p[@class='room']/text()")
position_1=dom.xpath("//div[@class='list-box']/ul[@class='house-list']/li/div[@class='des']/p/a[1]/text()")
position_2=dom.xpath("//div[@class='list-box']/ul[@class='house-list']/li/div[@class='des']/p/a[2]/text()")
price=dom.xpath("//div[@class='money']/b/text()")
for i in range(len(title)):
print('标题为:',title[i].strip())
print('面积为:',area[i].strip().replace(' ',''))
print('位置为:',position_1[i]+'\t'+position_2[i])
print('价格为:',str(price[i])+'元/每月')
print('----------分割线----------')
time.sleep(2)
 系统已结题
11月28日
系统已结题
11月28日 已采纳回答
11月20日
创建了问题
11月14日
已采纳回答
11月20日
创建了问题
11月14日




