
只抓取网页中的文字,不需要图片链接什么的,说是只需要15行代码就可以做到,代码应该怎么写?

用python美丽汤爬虫抓取网页中自己的姓名怎么弄代码?

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


3条回答 默认 最新
 CSDN专家-showbo 2021-11-25 09:04关注
CSDN专家-showbo 2021-11-25 09:04关注爬取题主问题中的名字,自己改下css选择器
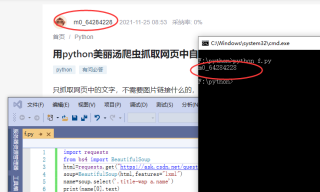
import requests from bs4 import BeautifulSoup html=requests.get("https://ask.csdn.net/questions/7578578",headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36 Edg/96.0.1054.29'}).text soup=BeautifulSoup(html,features="lxml") name=soup.select('.title-wap a.name')#自己改下css选择器 print(name[0].text)有帮助麻烦点下【采纳该答案】,谢谢~~有其他问题可以继续交流~
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2021-11-25 08:53回答 3 已采纳 爬取题主问题中的名字,自己改下css选择器 import requests from bs4 import BeautifulSoup html=requests.get("https://ask.
- 2022-08-17 17:07回答 3 已采纳 因为元素里的你要的内容是通过 ajax 请求动态加载的,可以浏览器抓包去看下,你想要的这条数据到底是哪个请求返回的,找到真正的请求,然后模拟发送就行了
- 2022-02-24 11:15回答 2 已采纳 那个网站啊.你看下是不是写在接口中.F12开发者模式.选择XHR看下
- 2020-11-29 16:04weixin_39903477的博客 使用bs4解析源码,获取歌曲名和歌曲ID;调用网易云歌曲API,获取歌词;将歌词写入文件,并存入本地。本文的意图是获取网易云音乐的歌词,并将歌词存入到本地文件。全体的效果图如下所示:赵雷的歌曲本文以歌谣歌神...
- 2021-09-21 22:16回答 1 已采纳 request.encoding = request.apparent_encoding
- 2021-08-07 13:04回答 3 已采纳 你可以用time模块进行计时,每过10分钟先用os.system()重新打开程序,然后调用sys.exit()关闭旧进程如果有用,希望采纳哦~
- 2022-04-05 22:09回答 3 已采纳 因为 个别标签字典中没有bond_nm和bond_nm_tip键 data2 = data_get['bond_nm'] data5 = data_get['bond_nm_tip']
- 2020-09-08 05:56weixin_26711425的博客 什么是网页抓取? Web Scraping is a technique employed to extract large amounts of data from websites whereby the data is extracted and saved to a local file in your computer or to...
- 2018-08-25 08:43回答 4 已采纳 楼主问的可能有点不清楚,我的理解是:https://zh.flightaware.com/live/airport/+{机场代号} 楼主有几千个机场代号,需要爬取这几千个URL的https://zh
- 2022-03-11 17:52回答 2 已采纳 re模块,正则表达式,split切分
- 2022-04-10 22:05回答 2 已采纳 安装这两个插件 然后设置颜色主题 或者你也可以安装其它你喜欢的然后颜色主题插件
- 2022-02-21 17:31程序员孔乙己的博客 网络安全是保护网络、系统和程序免受数字攻击的做法。据估计, 2019 年该行业价值 1120 亿美元,...根据 Stack Overflow 的说法,Python 在过去几年的增长令人难以置信,现在它被认为是所有行业中最受欢迎的语言之一。
- 2021-11-27 19:16回答 2 已采纳 该页面数据是动态加载的,需要用此链接用post请求去获取https://www.xuetangx.com/api/v1/lms/get_product_list/?page=1
- 2023-11-30 08:30Q_3461074420的博客 (2)查看基于Python的爬虫设计与数据分析的首页信息:基于Python的爬虫设计与数据分析的首页信息包含了首页、公告栏、旅游资讯、景点信息、我的(我的账户、我的收藏、个人中心)。 (3)公告栏:用户可以查看后台...
- 2023-06-29 16:00weixin_ZYKJ985的博客 基于Python的爬虫设计与数据分析主要功能模块包括轮播图(轮播图管理)公告栏管理(公告栏)资源管理(旅游资讯、资讯分类)系统用户(管理员、旅游用户)模块管理(地区分类、景点等级、景点信息、景点订票),采取...
- 没有解决我的问题, 去提问


问题事件
 系统已结题
12月3日
系统已结题
12月3日 已采纳回答
11月25日
已采纳回答
11月25日-
创建了问题
11月25日
悬赏问题
- ¥15 netty整合springboot之后自动重连失效
- ¥15 悬赏!微信开发者工具报错,求帮改
- ¥20 wireshark抓不到vlan
- ¥20 关于#stm32#的问题:需要指导自动酸碱滴定仪的原理图程序代码及仿真
- ¥20 设计一款异域新娘的视频相亲软件需要哪些技术支持
- ¥15 stata安慰剂检验作图但是真实值不出现在图上
- ¥15 c程序不知道为什么得不到结果
- ¥40 复杂的限制性的商函数处理
- ¥15 程序不包含适用于入口点的静态Main方法
- ¥15 素材场景中光线烘焙后灯光失效