

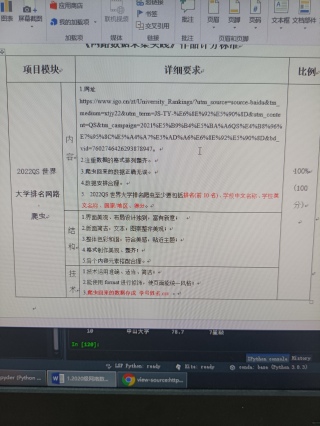
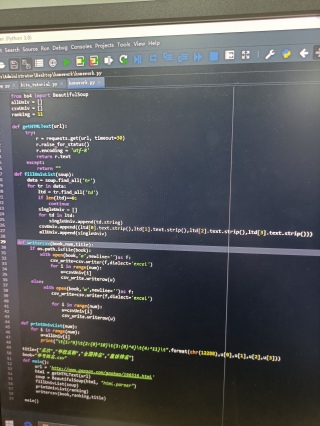

看了一下你问了几个没人解答,刚好刷到,帮你写一下,仅供参考。
import datetime
import time
from lxml import etree
import requests
import logging
BASE_URL='https://www.igo.cn/zt/University_Rankings/'
def scrape_url(url):
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
print(datetime.date.today(),time.strftime("%H:%M:%S"),'正在爬取网站为:{} ...'.format(url))
try:
response=requests.get(url,headers=headers)
response.encoding='gb2312'
if response.status_code==200:
return response.text
except requests.RequestException:
logging.error('error occurred while scraping %s',url,exc_info=True)
def parser_html():
html=scrape_url(BASE_URL)
dom=etree.HTML(html)
xp=dom.xpath('//tr/td[1]/text()')
xp_1=dom.xpath('//tr/td[2]/text()')
xp_2=dom.xpath('//tr/td[3]/text()')
xp_3=dom.xpath('//tr/td[4]/text()')
xp_4=dom.xpath('//tr/td[5]/text()')
for i in range(0,201):
print('排名:'+str(xp[i].replace('/td>',''))+'\t',
'中文名:'+xp_1[i]+'\t',
'英文名:'+xp_2[i]+'\t',
'国家/地区:'+xp_3[i]+'\t',
'得分:'+str(xp_4[i]))
if __name__ == '__main__':
parser_html()
上面代码是获取排行榜的数据,其中数据都打印出来了,你可自行运行一下参考,csv一块比较简单,可以搜搜csdn文件,把对应数据写进去就好了,如有帮助,给个采纳 蟹蟹~
 分享
分享 系统已结题
12月27日
系统已结题
12月27日 已采纳回答
12月19日
创建了问题
12月14日
已采纳回答
12月19日
创建了问题
12月14日


