python在进行excel到word邮件合并,循环提取时,无法直接生成在一个word文档内。
from docxtpl import DocxTemplate,InlineImage
from docx.shared import Cm
from mailmerge import MailMerge #邮件合并
import jinja2
import xlrd #excel读取
def Covert_Excel_To_Word():
# 打开Excel文件
workbook = xlrd.open_workbook(r"统计表.xls")
sheet = workbook.sheet_by_index(0)
nrow = sheet.nrows #获取excel最大行数
word_path = "信息卡.docx"
contexts = []
# 打开指定Word模板
for i in range(2,nrow):
word = DocxTemplate("信息卡.docx")
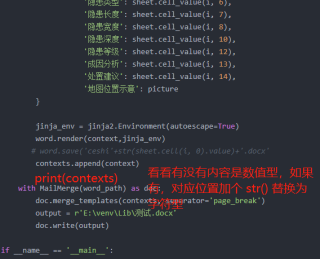
picture = InlineImage(word,'E:/venv/Lib/a.jpg',width=Cm(3))
context = {'序号': sheet.cell_value(i, 0),
'病害体编号': sheet.cell_value(i, 1),
'道路名称': sheet.cell_value(i, 2),
'详细位置描述': sheet.cell_value(i, 3),
'中心坐标_X': sheet.cell_value(i, 4),
'中心坐标_Y': sheet.cell_value(i, 5),
'隐患类型': sheet.cell_value(i, 6),
'隐患长度': sheet.cell_value(i, 7),
'隐患宽度': sheet.cell_value(i, 8),
'隐患深度': sheet.cell_value(i, 10),
'隐患等级': sheet.cell_value(i, 12),
'成因分析': sheet.cell_value(i, 13),
'处置建议': sheet.cell_value(i, 14),
'地图位置示意': picture
}
jinja_env = jinja2.Environment(autoescape=True)
word.render(context,jinja_env)
# word.save('ceshi'+str(sheet.cell(i, 0).value)+'.docx'
contexts.append(context)
with MailMerge(word_path) as doc:
doc.merge_templates(contexts, separator='page_break')
output = r'E:\venv\Lib\测试.docx'
doc.write(output)
if __name__ == '__main__':
Covert_Excel_To_Word()
###### Traceback (most recent call last):
File "E:\venv\Lib\word插图测试1.py", line 44, in <module>
Covert_Excel_To_Word()
File "E:\venv\Lib\word插图测试1.py", line 39, in Covert_Excel_To_Word
doc.merge_templates(contexts, separator='page_break')
File "D:\python\lib\site-packages\mailmerge.py", line 234, in merge_templates
self.merge(parts, **repl)
File "D:\python\lib\site-packages\mailmerge.py", line 254, in merge
self.__merge_field(part, field, replacement)
File "D:\python\lib\site-packages\mailmerge.py", line 266, in __merge_field
text_parts = text.replace('\r', '').split('\n')
AttributeError: 'float' object has no attribute 'replace'
Traceback (most recent call last):
File "E:\venv\Lib\word插图测试1.py", line 44, in <module>
Covert_Excel_To_Word()
File "E:\venv\Lib\word插图测试1.py", line 39, in Covert_Excel_To_Word
doc.merge_templates(contexts, separator='page_break')
File "D:\python\lib\site-packages\mailmerge.py", line 234, in merge_templates
self.merge(parts, **repl)
File "D:\python\lib\site-packages\mailmerge.py", line 254, in merge
self.__merge_field(part, field, replacement)
File "D:\python\lib\site-packages\mailmerge.py", line 266, in __merge_field
text_parts = text.replace('\r', '').split('\n')
AttributeError: 'float' object has no attribute 'replace'
能直接循环提取完后,保存在一个文档内吗