
from lxml import etree
import requests
import csv
f=open(r'C:\Users\86182\Desktop\jinan.csv','wt',newline='',encoding='utf-8')
writer=csv.writer(f)
writer.writerow(('name','price','address'))
urls=['https://jn.newhouse.fang.com/house/asp/trans/buynewhouse/default.htm?page={}&pricesort='.format(str(i)) for i in range(1,3)]
headers={
'user-agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36'
}
for url in urls:
html=requests.get(url,headers=headers)
selector=etree.HTML(html.text)
infos=selector.xpath('//div[@class="imgInfo"]')
for info in infos:
name=info.xpath('/html/body/div[4]/div[1]/div[2]/ul/li/div[1]/div/p/a/text()')[0]
price=info.xpath('/html/body/div[4]/div[1]/div[2]/ul/li/div[2]/div[1]/span/text()')[0]
address=info.xpath('/html/body/div[4]/div[1]/div[2]/ul/li/div[2]/p[2]/a/text()')[0]
#time=info.xpath('')[0]
writer.writerow((name,price,address))
f.close()
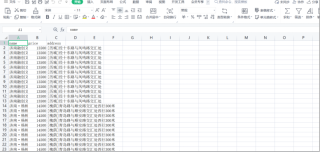
但在更换网址后就没有问题








