import requests
from bs4 import BeautifulSoup
import csv
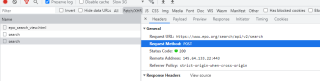
url='https://www.epo.org/search.html?q=hydrogen%20storage&resultsPerPage=100&sortOrder=1'
data_list=[]
res=requests.get(url)
print(res.status_code)
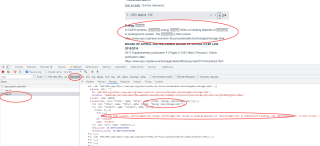
bs=BeautifulSoup(res.text,'html.parser')
reslist=bs.find_all('a',class_='headlink')
print(reslist)
最后一行出来的结果是'[]'
为什么啊