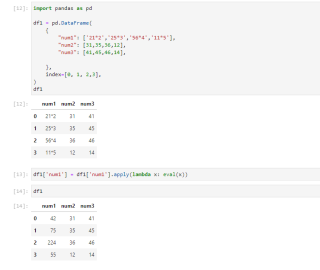
在使用pandas库时使用pandas.read.scv函数读取数据集后有一列数据为1234 * 1234 * 1234格式的(见附图),有没有一种快速处理的方法能将这列数据算出来,用for循环的话会算很久,下面是我的代码
for x in data["12anonymousFeature"]:
N = eval(str(x))
data["12anonymousFeature"] = data["12anonymousFeature"].replace(x, N)
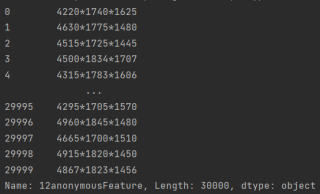

在使用pandas库时使用pandas.read.scv函数读取数据集后有一列数据为1234 * 1234 * 1234格式的(见附图),有没有一种快速处理的方法能将这列数据算出来,用for循环的话会算很久,下面是我的代码
for x in data["12anonymousFeature"]:
N = eval(str(x))
data["12anonymousFeature"] = data["12anonymousFeature"].replace(x, N)
 分享
分享 系统已结题
1月25日
系统已结题
1月25日 已采纳回答
1月17日
创建了问题
1月17日
已采纳回答
1月17日
创建了问题
1月17日