用requests库和bs4库爬取并解析网页内容
显示错误为: IndexError: list index out of range
代码如下:
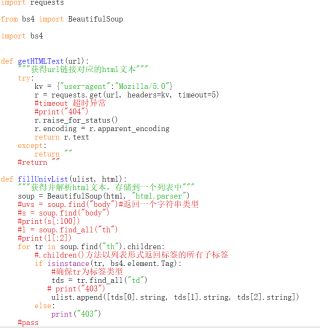
(url链接因版权问题就没有上传)
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
"""获得url链接对应的html文本"""
try:
kv = {"user-agent":"Mozilla/5.0"}
print("*")
r = requests.get(url, headers=kv)
#timeout 超时异常
print("*")
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
#return ""
def fillUnivList(ulist, html):
"""获得并解析html文本,存储到一个列表中"""
soup = BeautifulSoup(html, "html.parser")
#uvs = soup.find("body")#返回一个字符串类型
#s = soup.find("body")
#print(s[:100])
#l = soup.find_all("th")
#print(l[:2])
for tr in soup.find("th").children:
#.children()方法以列表形式返回标签的所有子标签
if isinstance(tr, bs4.element.Tag):
#确保tr为标签类型
tds = tr.find_all("td")
# print("403")
ulist.append([tds[0].string, tds[1].string, tds[2].string])
else:
print("403")
#pass
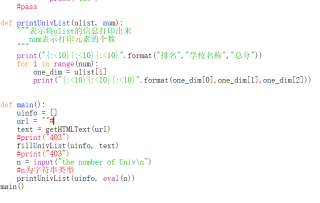
def printUnivList(ulist, num):
"""表示将ulist的信息打印出来
num表示打印元素的个数
"""
print("{:<10}{:<10}{:<10}".format("排名","学校名称","总分"))
for i in range(num):
one_dim = ulist[i]
print("{:<10}{:<10}{:<10}".format(one_dim[0],one_dim[1],one_dim[2]))
def main():
uinfo = []
url = "https://www.shanghairanking.cn/rankings/bcur/202211"#软科链接
text = getHTMLText(url)
#print(text[0])
#print("403")
fillUnivList(uinfo, text)
#print("403")
n = input("the number of Univ\n")
#n为字符串类型
printUnivList(uinfo, eval(n))
main()