问题遇到的现象和发生背景
我有一大堆CSV文件,表头都是这样的:

我每次只需要读取最后一行的日期数据,而不必加载整个CSV文件
问题相关代码,请勿粘贴截图
我现在是用这样的语句来读取的。
df = pd.read_csv(path,encoding='gbk')
result = df.iloc[-1,1]
print(result)
我想要达到的结果
我希望不必加载整个CSV文件,仅仅是读取最后一行的数据,节约资源提高效率

我有一大堆CSV文件,表头都是这样的:
我现在是用这样的语句来读取的。
df = pd.read_csv(path,encoding='gbk')
result = df.iloc[-1,1]
print(result)
我希望不必加载整个CSV文件,仅仅是读取最后一行的数据,节约资源提高效率
 分享
分享
可以考虑用file_read_backwards从文件末尾读取,然后处理字符串得到所需的数据(这里安装file_read_backwards包后,需要去file_read_backwards.py中手动改下配置,添加'gbk'编码支持
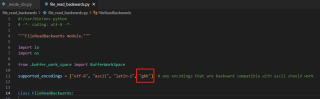
import pandas as pd
import time
from file_read_backwards import FileReadBackwards
epoch = 100
# pd.read_csv test
start = time.time()
for _ in range(epoch):
data = pd.read_csv('20220821_s.csv', encoding = 'gbk')
res = data.iloc[-1, :]
end = time.time()
elapse = (end - start) / epoch
print(f'pd.read_csv cost {elapse} per epoch\ndata: {res}') # 0.023s
# FileReadBackwards test
start = time.time()
for _ in range(epoch):
with FileReadBackwards('20220821_s.csv', encoding = 'gbk') as f:
res = f.readline()
end = time.time()
elapse = (end - start) / epoch
print(f'FileReadBackwards cost {elapse} per epoch\ndata: {res}') # 9.007e-5s
 系统已结题
8月30日
系统已结题
8月30日 已采纳回答
8月22日
创建了问题
8月22日
已采纳回答
8月22日
创建了问题
8月22日




